Navigating Data Governance: A Guiding Tool for Regulators
31.10.2024Introduction
In today’s data-driven world, the importance of robust data governance is more critical than ever. As digital ecosystems rapidly expand, the surge in mobile broadband subscriptions, internet traffic, and the number of internet users, now surpassing 5.4 billion[1], has transformed data into a vital asset. This data—whether generated by businesses, governments, or individuals—fuels innovation, enhances decision-making, and accelerates the digital transformation of economies and societies. However, the immense volume of data being generated, collected, and processed brings with it substantial challenges for regulators. Ensuring the responsible use, protection, and governance of this data is paramount to safeguarding personal data and privacy, fostering trust, and enabling sustainable growth in the digital age.
|
Data governance refers to the comprehensive framework that encompasses the people, policies and processes overseeing how data decisions are made and implemented throughout the data lifecycle. It includes strategic, legal, and regulatory considerations to minimize risks, ensure accountability, and optimize data assets. It is important to note that there may be similarities and variations in how different countries define concepts related to data governance. For example, the definition of “personal data” or “sensitive data” may differ from one country to another, impacting data governance practices. Source: UNCTAD (2024) Data for development, https://unctad.org/publication/data-development; UNCTAD (2023) How to make data work for the 2030 Agenda for Sustainable Development, https://unctad.org/board-action/how-make-data-work-2030-agenda-sustainable-development; UNCTAD (2016), Data protection regulations and international data flows: Implications for trade and development, https://unctad.org/publication/data-protection-regulations-and-international-data-flows-implications-trade-and. For a comprehensive, country-level definition of the term data governance, see: World Bank, World Development Report 2021, https://wdr2021.worldbank.org/the-report |
This article provides practical guidance to ICT regulators, other regulatory agencies (including data protection authorities ), and stakeholders dealing with data governance, in monitoring and guiding organizations’ data governance practices, focusing on data classification, data interoperability, data availability, quality and integrity, data access and sharing, and data security and data protection and privacy, providing a clear roadmap for regulatory action, explaining key roles and responsibilities for data governance to ensure that organizations have an adequate data governance structure in place and maintain proper documentation and reporting data governance practices and better understand and address the complex data protection requirements.
Within this context, data lifecycle management frameworks are important to establish, as examined in and methodologies provided in the article. This ensures that all stages, from data collection and storage to usage, sharing, and disposal, are handled with appropriate controls and safeguards, thereby maintaining data integrity, security, and compliance with relevant regulations.
ICT Regulators recognized the importance of developing appropriate data governance policies to strike a balance between safeguarding individual and organizational data protection and privacy, security, and integrity and enabling cross-border data flows to operate, as part of the GSR-24 best practice guidelines they adopted on helping to chart the course of transformative technologies for positive impact.[2]
This article further examines the challenges and opportunities posed by AI, IoT, blockchain, cross-border data flows for international contexts, and regulatory approaches to managing data transfer and protection across borders. Building public trust, engagement, and capacity in data governance is crucial, highlighting the need for transparency, accountability, public involvement, and collaboration across government and with other key stakeholders from the private sector, civil society, and academia. Innovative approaches to data governance, such as data sandboxes, trusts, cooperatives, commons, collaboratives, and marketplaces, are being considered and studied as potential mechanisms to support implementation. However, it is important to note that these are experimental in nature and may not be applicable or effective in all jurisdictions. While they offer flexible and agile solutions to address contemporary data governance challenges, their suitability and success can vary depending on the specific legal, regulatory, and societal context.[3]
Practical checklists are included throughout the article to guide organizations in establishing responsible, robust, and compliant data governance frameworks and practices. These practices enhance data security, ensure accountability, support risk management, and facilitate transparent and effective regulatory oversight.
Data Classification
Data classification is a cornerstone of data governance, playing a crucial role in ensuring that data is properly managed, accessed, and protected based on its sensitivity, importance and usage. By systematically categorizing data into well-defined classifications, organizations—including ICT regulators and data protection authorities—can establish clear rules for data handling and security, enabling them to meet legal and operational requirements effectively. The most widely used classification categories include Secret, Confidential, Restricted, and Public, which provide a structured approach for prioritizing data protection measures.[4]
This process involves labeling data to indicate its confidentiality level, access restrictions, and handling requirements. The purpose of data classification is to ensure that data is managed according to its classification level, as defined by the organization’s data governance policies. This enables organizations to implement appropriate controls, protect sensitive information, and ensure compliance with relevant laws and regulations.[5]
Data classification is a critical process that varies significantly across jurisdictions and organizations, with each region or country potentially adopting different definitions and classifications for data. This variation arises due to differing legal frameworks, cultural norms, and regulatory priorities, which can influence how data is categorized and managed. [6] For example, what one jurisdiction might classify as ‘sensitive personal data,’ another might label simply as ‘personal data’ without the same level of required protection. “Sensitive” at an organizational level can relate to sensitivities that have nothing to do with the type of personal data (e.g., national security data, high-value data, etc.). This lack of uniformity can create complexities for organizations operating across borders, as they must navigate and comply with multiple, sometimes conflicting, data classification standards. [7]
Why Data Classification is Essential for Regulators For ICT regulators, data classification provides a framework to manage and protect data shared across telecommunications and digital platforms, ensuring that sensitive information such as subscriber details and communication logs are only accessed by authorized personnel. For example, an ICT regulator might classify network data that includes user traffic patterns as Confidential, limiting access to internal analysts while ensuring it is not shared publicly to prevent misuse. Similarly, data protection authorities benefit from data classification as it allows them to clearly define and enforce the level of protection required for different types of personal data, ensuring compliance with data protection laws or national privacy regulations. For instance, health data collected during a pandemic might be categorized as Restricted or Confidential based on its potential impact on individual privacy if disclosed. |
Data Classification Framework: Secret, Confidential, Restricted, and Public
The data classification framework presented in this article uses four categories—Secret, Confidential, Restricted, and Public—each serving a distinct role in defining data sensitivity and access requirements.
Secret Data includes the most sensitive information, the disclosure of which could result in severe harm to national security, public safety, or economic stability.
- Example: An ICT regulator managing data on national critical information infrastructure, such as energy grid vulnerabilities or emergency response communication channels, would classify this data as secret. Such data requires the highest level of protection, with access limited to top-tier officials and encrypted storage solutions.
- Handling Requirements: Secret data must be stored in secure locations, with stringent access controls, continuous monitoring, and multi-factor authentication to ensure that only authorized personnel can access it.
Confidential Data refers to information that, if exposed, can lead to significant damage to an organization or individuals. This category typically includes personal data, such as employee or customer information, as well as sensitive internal details like financial records, trade secrets, or proprietary business strategies. Protecting this type of data is crucial to prevent reputational harm, legal penalties, or financial losses.
- Example: A data protection authority might classify personal information collected for a national identity program—such as biometric data and identity numbers—as confidential. Unauthorized access to this data could lead to identity theft or misuse, necessitating robust access controls and encryption.
- Handling Requirements: Confidential data should be encrypted both at rest and in transit. Access must be restricted to personnel on a need-to-know basis, and periodic audits should be conducted to ensure compliance.
Restricted Data includes internal information that, while not highly sensitive, should not be disclosed outside the organization due to potential misuse.
- Example: An ICT regulator might classify internal meeting notes or preliminary research findings on new cybersecurity regulations as Restricted data. While the information is not highly sensitive, disclosing it prematurely could impact public perception or provide unfair advantages to certain stakeholders.
- Handling Requirements: Restricted data should have access controls that limit its use to specific internal teams, and it should not be shared outside the organization without appropriate permissions.
Public Data is information intended to be openly accessible and shared without restrictions. If accessed by anyone, it poses minimal risk.
- Example: A data protection authority’s annual report on data breach statistics or a public consultation paper on proposed regulations would be classified as public data. This data is meant to be freely available to inform and engage the public.
- Handling Requirements: Public data does not require stringent security measures but should be monitored for integrity to prevent tampering or unauthorized changes.
By incorporating data classification into the broader data governance framework, regulators can ensure that data is managed responsibly, securely, and in alignment with regulatory requirements. For instance, a national data protection authority can use data classification to create clear rules for handling personal data collected from online platforms, while an ICT regulator can apply classification to secure data shared across telecommunications networks.
Ultimately, data classification helps organizations and regulators protect sensitive information, promote transparency, and ensure compliance, supporting effective data assets management and utilization in a rapidly evolving digital landscape.
Checklist for Data Classification
Regulators can use the following checklist to guide organizations under their purview in implementing effective and compliant data identification processes.
|
Establish a Data Inventory |
| ☐ Create a comprehensive inventory of all data assets within the organization. |
| ☐ Document the source, format, and ownership of each data asset. |
Assess Data Value and Risk |
| ☐ Evaluate the value of each data asset to the organization. |
| ☐ Assess the potential risks associated with each data asset. |
Categorize Data Types |
| ☐ Classify data assets into categories such as: Secret, Confidential, Restricted, and Public (it has to be noted that countries can have different categories of data in accordance with their data protection legislation, such as top secret, confidential, personal, non-personal etc. When classifying data assets into categories, organizations should follow their country’s respective data protection laws and regulations). |
| ☐ Document the classification criteria for each data category. |
| ☐ Try to limit the number of data classification levels. |
| ☐ For non-restricted data, have an “open by default” approach. |
| ☐ Ensure that the data classification framework is adapted to organizational needs. For example, it should take into account data protection requirements for personal data and be appropriate for cloud storage. |
| ☐ Make sure there is mandatory application/implementation of the classification framework and provide appropriate training on implementation. |
Ensure Compliance |
| ☐ Verify compliance with relevant data protection regulations and standards. |
| ☐ Ensure data handling practices align with legal and regulatory requirements. |
Implement Data Protection Measures |
| ☐ Develop and implement protective measures for sensitive and very sensitive data. |
| ☐ Ensure appropriate security controls are in place to prevent unauthorized access. |
Review and Update Inventory Regularly |
| ☐ Schedule regular reviews and updates of the data inventory. |
| ☐ Ensure the inventory reflects any changes in data assets and their classifications. |
Data Interoperability
Data interoperability is defined as the ability to access, process, and exchange data between multiple sources or systems. Interoperable data can increase the quality of interventions and policies through data-informed decision-making. Considering data interoperability at the beginning of data planning and collection can help anticipate and consider potential data use cases in the future. [8]
Data interoperability is essential for enabling seamless data exchange between systems and organizations. For instance, the European Union’s Digital Single Market strategy underscores the significance of data interoperability in enhancing digital services and fostering innovation across member states.[9] Promoting interoperability facilitates the effective sharing of data across diverse systems, leading to comprehensive insights and improved regulatory capabilities. For example, integrating data from different telecom operators allows regulators to obtain a holistic view of the industry, enhancing their ability to make informed decisions and enforce regulations more effectively. Systems created by different entities should seamlessly interact without limitations. Each restriction acts as a barrier to generating public value through a data ecosystem and deters organizations from participating.
A lack of data interoperability can be due to multiple factors, such as duplicative data (e.g., recording the same data twice) or disorganized data where it is unclear what information is being recorded, how it is sorted, for what purpose, and under which format(s) it is recorded. Unclear and disorganized data can potentially lead to system glitches, causing organizations to make uninformed decisions and limit information exchange.
Figure 1. Data Interoperability Maturity Model
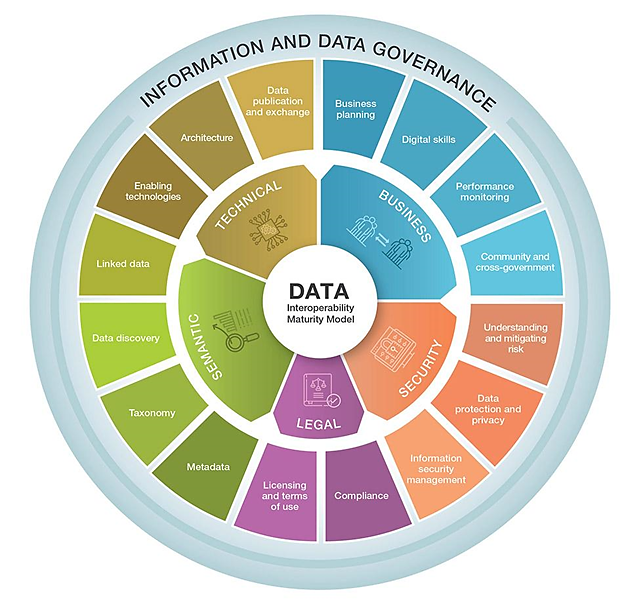
The Data Interoperability Maturity Model (DIMM)[10] (Figure 1), is a useful tool for measuring an agency’s progression across five key themes of data interoperability. The business theme assesses the operational maturity for producing, consuming, and sharing data (e.g., integrating real-time data feeds from various departments to improve decision-making). The security theme focuses on awareness and response to security risks, exemplified by implementing stringent access controls and regular security audits to protect sensitive data. The legal theme involves ensuring legal support for data interoperability, such as establishing clear data-sharing agreements and compliance with data protection laws. The semantic theme deals with data structures that enable the meaning of exchanged information to be understood by both people and systems, like adopting standardized metadata and taxonomies to ensure data consistency across platforms. Lastly, the technical theme encompasses the technology supporting data interoperability, including systems and services that facilitate seamless data exchange, such as using APIs[11] to integrate disparate data systems within the agency. Each theme is assessed through categories with five maturity levels: initial, developing, defined, managing, and optimizing, allowing agencies to identify their current maturity, plan improvements, and track progress over time.
Checklist for Data Interoperability
This detailed checklist is designed to help regulators ensure robust and compliant data governance practices within organizations. Organizations can enhance their data interoperability by focusing on specific actions and detailed requirements, leading to better decision-making and regulatory compliance.
|
Planning and Strategy |
| ☐ Initial Planning: Ensure data interoperability requirements are incorporated into the initial planning stages of data projects. |
| ☐ Interoperability Strategy: Develop a detailed data interoperability strategy that aligns with organizational goals and complies with regulatory standards. |
| ☐ Use Case Identification: Identify and document potential future data use cases to guide data collection and storage practices. |
|
Business Theme |
| ☐ Operational Maturity: Assess and document the operational maturity for producing, consuming, and sharing data. |
| ☐ Integration of Data Feeds: Integrate real-time data feeds from various departments, such as finance, human resources, and operations, to enhance decision-making processes. |
|
Security Theme |
| ☐ Access Controls: Implement and enforce stringent access controls to safeguard sensitive data, including role-based access and multi-factor authentication. |
| ☐ Security Audits: Conduct regular security audits to identify vulnerabilities and ensure compliance with security standards. |
| ☐ Risk Response: Develop and maintain a risk response plan to address identified security risks promptly. |
|
Legal Theme |
| ☐ Data-Sharing Agreements: Establish and maintain clear data-sharing agreements that comply with relevant data protection laws and regulations. |
| ☐ Compliance Reviews: Regularly review and update legal frameworks and agreements to ensure ongoing compliance with evolving data protection laws. |
|
Semantic Theme |
| ☐ Standardized Metadata: Adopt and implement standardized metadata schemas to ensure data consistency across platforms. |
| ☐ Taxonomies and Ontologies: Develop and use taxonomies and ontologies that facilitate the understanding of data across different systems and stakeholders. |
|
Technical Theme |
| ☐ API Integration: Use APIs to integrate disparate data systems, ensuring seamless data exchange. |
| ☐ Infrastructure Maintenance: Regularly update and maintain the technical infrastructure supporting data interoperability to prevent obsolescence. |
| ☐ Interoperability Tools: Implement and utilize tools and technologies that facilitate data interoperability, such as data transformation and mapping software. |
|
Monitoring and Evaluation |
| ☐ DIMM Assessment: Use the Data Interoperability Maturity Model (DIMM) or similar assessment models to assess the organization’s maturity across five themes: business, security, legal, semantic, and technical. |
| ☐ Maturity Levels: Identify the current maturity level (initial, developing, defined, managing, optimizing) for each theme. |
| ☐ Improvement Plan: Develop and implement a plan to advance through the maturity levels, setting specific, measurable goals. |
| ☐ Progress Tracking: Establish mechanisms to track progress and document improvements over time. |
|
Training and Awareness |
| ☐ Regular Training: Provide regular training sessions for staff on data interoperability principles, tools, and best practices. |
| ☐ Awareness Campaigns: Conduct awareness campaigns to highlight the importance of data interoperability and its benefits to the organization. |
|
Collaboration and Stakeholder Engagement |
| ☐ Inter-Departmental Collaboration: Foster collaboration between different departments to enhance data sharing and integration efforts. |
| ☐ External Partnerships: Engage with external partners, such as industry bodies and regulatory agencies, to promote data interoperability standards. |
| ☐ Stakeholder Involvement: Involve key stakeholders in the development and implementation of data interoperability strategies to ensure buy-in and support. |
|
Continuous Improvement |
| ☐ Policy Reviews: Regularly review and update data interoperability policies and procedures to reflect best practices and technological advancements. |
| ☐ Innovation Encouragement: Encourage continuous improvement and innovation in data management practices through regular feedback loops and pilot projects. |
Data Availability, Quality, and Integrity
For data to be genuinely useful, it must meet high standards of data availability, quality, and integrity, which in turn are foundational to ensuring accuracy, consistency, and reliability. Data availability ensures that necessary data is accessible when needed, which is crucial during regulatory audits or emergency response situations. Without availability, even the most accurate or consistent data becomes irrelevant if it cannot be accessed in a timely manner. [12]
Data quality encompasses dimensions such as completeness and validity. Completeness ensures all required information is present, such as subscriber records, including contact details, while validity ensures data conforms to required formats and standards, like phone numbers adhering to the international E.164 format[13]. High-quality data directly impacts accuracy by ensuring that the data correctly reflects real-world entities. For instance, accurate mobile subscriber data means figures precisely match the actual number of active subscribers, not just the total number of issued SIM cards. [14]
Data integrity safeguards against unauthorized alterations, maintaining the trustworthiness and authenticity of the data. This integrity is crucial for ensuring consistency and reliability. Consistency means that data remains uniform and stable across various datasets and platforms, such as subscriber data recorded by telecom operators being consistent with data reported to regulatory bodies. Reliability implies that the data is dependable and can be trusted over time for consistent decision-making. Reliable data ensures that trends and patterns observed reflect reality, accurately tracking the uptake of new telecom services over multiple years. [15]
Prioritizing data availability, quality, and integrity is essential because these elements ensure that data is accessible, accurate, consistent, and reliable, forming the backbone of effective data-driven decision-making for regulators.
Standards and Best Practices for Data Quality Management
Data Quality Management involves the processes and methodologies used to monitor, measure, and improve data quality. Adhering to established standards and best practices is essential for ensuring data integrity and utility. Data Quality Dimensions encompass various critical aspects to ensure the integrity and utility of data:
- Accuracy is paramount. For instance, in the telecom sector, ensuring the identifier of a person matches a specific location is crucial. While physical or postal addresses may not exist in some countries, accurately linking a subscriber’s identifier to a geographic location is essential for avoiding regulatory fines and ensuring emergency services can locate subscribers when needed.
- Consistency across all systems and platforms is essential; for instance, ICT usage statistics should align between billing systems and network performance monitoring tools to guarantee accurate service quality assessments.
- Completeness ensures all necessary data is present, as missing contact details in subscriber records can impede effective communication during service outages or updates.
- Timeliness demands that data be up-to-date, such as processing call detail records (CDRs) in real-time to aid in fraud detection and prevention.
- Validity requires data to comply with specified formats and standards, exemplified by phone numbers adhering to the international E.164 format for global interoperability.
- Uniqueness is vital to avoid duplicate records, ensuring each subscriber has a unique identifier to prevent multiple entries that could distort market analysis.
Data Validation and Error Detection Techniques
Effective data validation and error detection are critical for maintaining high data quality, particularly for data protection and ICT regulators. Data validation techniques ensure data accuracy and consistency. For example, format validation ensures data conforms to required formats, such as ensuring dates in service activation records are in the DD/MM/YYYY format to avoid confusion, like avoiding misinterpretation of “03/04/2023” as either March 4th or April 3rd. Cross-field validation checks for logical consistency between related fields, such as ensuring that a data plan’s start date is not after its end date, similar to preventing billing errors by verifying that subscription start dates precede their respective end dates. Reference checks verify data against external datasets, such as validating subscriber locations against national address databases to ensure accurate service provisioning, like confirming emergency service dispatches to correct addresses. [16]
Error detection techniques help maintain data integrity and reliability. Duplicate detection identifies and merges duplicate records to maintain uniqueness, such as merging multiple entries of the same subscriber across different telecom services, akin to consolidating multiple SIM card registrations for a single user. Range checks verify that data values fall within expected ranges, ensuring, for example, that signal strength measurements are within the typical range for the technology used, much like verifying that 4G signal strengths are neither too weak nor implausibly strong. Consistency checks ensure data is consistent across different datasets and platforms, such as cross-checking reported service outages with network performance data. This is similar to ensuring customer complaints align with recorded service issues. Statistical methods use techniques like standard deviation to identify outliers and anomalies, such as detecting unusual spikes in data usage that may indicate fraudulent activity, akin to flagging a sudden, massive increase in data consumption by a single user.[17]
Data governance roles and responsibilities at organizational level
A successful data governance program is fundamentally built upon its people: data governance specialists, alongside key business and IT personnel, who establish and maintain workflows to meet the organization’s data governance needs. The roles and responsibilities within data governance can vary across organizations, but several key stakeholders and units are commonly involved.[18]
Assigning roles and responsibilities to certain personnel, departments, organizations, or coalitions to oversee data at all lifecycle stages provides accountability for who will handle what data. Understanding who owns data and who is responsible for its management is crucial for effective data governance. This section delves into the roles in data governance, and the responsibilities and obligations that come with these roles. By clarifying these aspects, regulators can ensure accountability and proper data handling.
Data Governance Committee
This high-level, cross-functional unit comprises experts from various business areas. The committee’s primary goal is to define and control all data governance initiatives. Optimal effectiveness is achieved when subject matter experts (e.g., data engineers and data security managers) collaborate with system managers (e.g., solution architects and data analytics managers) and business units (e.g., sales specialists). For instance, the United Kingdom’s Government Data Quality Hub operates similarly by integrating expertise across departments to maintain high data quality standards.[19]
In a complex data system with multiple uses and users, a data governance committee is assigned the task of establishing and promulgating data stewardship policies and procedures. This committee should be cross-functional and include management representatives, legal counsel, the data system administrator, data providers, data managers, privacy and security experts, and data users from across the organization.
Chief Data Officer (CDO)
The CDO is typically the leader and initiator in data governance, responsible for defining and implementing data policies, standards, and procedures. Their role ensures that data is managed consistently, accurately, securely, and in compliance with regulations. Additionally, the CDO promotes data literacy within the organization, ensuring that data is effectively used to achieve business objectives. These responsibilities may also fall to a Chief Digital Officer in some organizations. In the United Kingdom, local councils often appoint a CDO to lead data governance efforts, ensuring the effective management and utilization of public data.[20] Each Bureau and Office within the Federal Communication Commission (FCC) in the United States has an Information and Data Officer whose role is to ensure better use of data and data-driven decision-making. In supporting the mission and activities of the Commission, they lead and collaborate on internal and external data strategy efforts[21].
Data Steward
While data is being processed and integrated, it is critical to understand data stewardship, which defines who has what kinds of data and who will be responsible for processing and managing the data. Good data stewardship practices prioritize data to be accessible, usable, safe, and trusted throughout the data lifecycle. Many government institutions are already active data stewards of vast data sets with macro and micro data. Macro data generally does not include personally identifiable information (PII)[22]. Examples of a macro dataset are the ITU’s data hub for ICT statistics and regulatory information and the World Bank’s data repositories for annual country diagnostic reports.[23] Microdata,[24] on the other hand, provides information about characteristics of individuals or entities such as households, business enterprises, facilities, farms, or even geographical areas such as villages or towns to design and target interventions, formulate policies, and monitor the impact of initiatives.
Data stewardship involves appointing data stewards responsible for overseeing data quality, security, and usability within their respective domains. Data stewards play a vital role in implementing data governance policies and standards, ensuring compliance, and addressing data-related issues.
Often regarded as the “guardian” of data, the data steward oversees data governance initiatives and addresses any anomalies. Their role is critical in maintaining data integrity and quality. An example of this role in practice can be found in the Netherlands, where data stewards in government agencies ensure compliance with strict data privacy laws and regulations.[25] Implement policies, procedures, and practices to ensure data integrity, quality, and security. They are often assigned to specific business units or domains and act as the connector between IT and business departments. Data stewards are responsible for data quality, metadata management, data access, and ensuring data is trustworthy and used correctly. There are different types of data stewards, including domain data stewards, business data stewards, and system data stewards.[26]
Example: In a telecom company, the Chief Data Officer (CDO) sets data access and usage policies. Data stewards, who might be managers in different departments, ensure these policies are followed and maintain data integrity and security. If a data breach occurs, the data stewards are responsible for managing the response and rectifying any issues.
Data Custodians
Data custodians are responsible for implementing and maintaining the business and technical rules to manage a dataset, set by the data steward. Data custodians are accountable for ensuring the safe custody, transport, and storage of data.[27] Data custodians typically receive instructions from data stewards or chief data officers on what to do – they do not make decisions alone.
Solution Architect
This role entails creating and deploying technology solutions that align with an organization’s business objectives, particularly in the realm of data governance. Solution architects collaborate with key stakeholders to establish data governance frameworks, design robust data architectures, and execute effective data management strategies. In the context of a government agency implementing a new digital tax filing system, the solution architect would work with tax officials to define data governance policies ensuring the security and privacy of citizens’ financial data. They would design a data architecture that integrates various government databases while ensuring compliance with data protection laws. Additionally, they would implement processes for managing data access and retention, thereby reducing the risk of data breaches and ensuring the system’s integrity. The Australian government’s approach to data governance, including solution architects in integrating data management policies within technology solutions, exemplifies this role.[28]
Data Architect
Focused on creating and building data infrastructures, the data architect contributes to designing and implementing data governance policies and processes, ensuring they align with the organization’s data architecture. A data architect is a professional responsible for designing, deploying, and managing an organization’s data architecture. This role involves developing the framework for how data is collected, stored, managed, and used within an organization. Data architects ensure that data systems are scalable, secure, and efficient, and they play a critical role in aligning the data infrastructure with business objectives and technology strategies.
Given the wide range of skills and expertise required, it is crucial for organizations to have a dedicated data governance team or individual to drive the program. This is the approach taken by the Singaporean government, which has a dedicated data governance team within its Smart Nation and Digital Government Office.[29]
In addition, companies and organizations nowadays also often incorporate a Data Protection Officer (DPO) to ensure that the personal data of its staff, customers, providers or any other individuals is processed in compliance with the applicable data protection rules in place.[30]
Checklist for Data governance roles and responsibilities at organizational level
Regulators can use the following checklist to guide organizations under their purview in implementing effective and compliant processes related to data governance roles and responsibilities at organizational level.
|
Clarify Data Ownership Rights: |
| ☐ Define ownership: Clearly define who owns the data and under what conditions ownership can be transferred or shared. ☐ Establish policies: Develop and implement data ownership policies that outline the rights and responsibilities of data owners. |
|
Role of Data Governance Committee: |
| ☐ Form the committee: Establish a cross-functional data governance committee with representatives from various business units, IT, legal, and data security. ☐ Assign responsibilities: Clearly define the committee’s role in overseeing and guiding data governance initiatives. |
|
Role of Data Stewards and Custodians: |
| ☐ Appoint data stewards: Designate data stewards for each data domain to manage and oversee data governance. ☐ Define roles: Clearly define the roles and responsibilities of data stewards and custodians. |
|
Responsibilities of Chief Data Officer (CDO): |
| ☐ Assign CDO: If required by law or necessitated by the size of the organization, designate a Chief Data Officer to lead the data governance program. ☐ Implement policies: Ensure the CDO defines and implements data policies, standards, and procedures. |
|
Solution Architect and Data Architect Responsibilities: |
| ☐ Include Solution Architect: (Optional) Involve Solution Architects in designing and implementing technology solutions that align with data governance requirements. ☐ Assign Data Architect: (Optional) Ensure Data Architects contribute to the design and implementation of data infrastructures and align governance processes with data architecture. |
|
Develop and Implement Governance Policies: |
| ☐ Create policies: Develop data governance policies that address data quality, security, access, and compliance. ☐ Implement procedures: Establish procedures for ensuring data quality, security, and usability. |
|
Monitor and Review Roles and Responsibilities: |
| ☐ Conduct reviews: Regularly review and update roles and responsibilities to adapt to changing business and regulatory needs. ☐ Perform audits: Conduct periodic audits to ensure that all roles are performing their assigned responsibilities. |
|
Promote Data Literacy (Optional): |
| ☐ Train stakeholders: Provide training to ensure all stakeholders understand their roles in the data governance framework. ☐ Promote literacy: Encourage data literacy across the organization to support data-driven decision-making. |
|
Document and Communicate Governance Structure: |
| ☐ Document roles: Document the governance structure, roles, and responsibilities within the organization. ☐ Communicate structure: Share the governance structure with all relevant stakeholders. |
|
Ensure Accountability and Compliance: |
| ☐ Establish accountability: Set up accountability mechanisms for each role in the data governance framework. ☐ Ensure compliance: Regularly review policies and practices to ensure compliance with internal and external regulations. |
Data Access and Sharing
Data sharing is multifaceted; various methods are available for individuals, organizations, businesses, and countries to exchange data. By understanding these methods, regulators can enhance their grasp of data-sharing practices. Data sharing can occur at multiple levels, from individual to transnational exchanges, involving various stakeholders. For example, at a macro level, an international aid organization might share aggregated data on health outcomes across regions to help governments improve public health strategies. At a micro level, a local non-profit might share specific data on water usage with a government agency to aid in resource management.
Data access refers to the rules and protocols that dictate how data can be retrieved from the original data system. It covers internal, external, and public access. Government agencies are frequently bound by legal or statutory obligations to make data publicly accessible. Data sharing outlines the processes for transferring and utilizing data outside the original data system. |
Data access refers to the rules and protocols that dictate how data can be retrieved from the original data system. It covers internal, external, and public access. Government agencies are frequently bound by legal or statutory obligations to make data publicly accessible.
Data sharing outlines the processes for transferring and utilizing data outside the original data system.
Access to and sharing of data drive innovation and collaboration, but these must be carefully balanced with privacy concerns. Additionally, data as an intellectual property (IP) asset requires thorough management and protection. This section discusses policies governing digital data access and sharing, ensuring equitable and secure access. Concepts of open data and data protection and privacy, legal frameworks, and case studies of successful implementations are explored. Furthermore, the section covers IP in data governance, discussing licensing, data sharing agreements, and managing IP rights in collaborative environments.
Policies Governing Data Access and Sharing
Effective policies are essential to facilitate digital data access and sharing while protecting personal data and privacy and intellectual property. Regulators must create frameworks that promote data-driven innovation without compromising individuals’ rights or proprietary interests.
Ensuring compliance with security policies is accomplished by clearly specifying all activities related to handling data by data stewards as well as users. This includes stating who can access what data, for what purpose, when, and how. A governance plan should provide guidance about the appropriate managerial and user data activities for handling records throughout all stages of the data lifecycle, including acquiring, maintaining, using, and archiving or destroying both regular and secure data records. Additionally, the plan should specify requirements and mechanisms for de-identifying PII data in order to protect individual data and privacy (e.g., by removing all direct and indirect identifiers from PII data).
Ensuring that data dissemination activities comply with federal, state, and local laws is a key organizational responsibility. The release or sharing of any data (e.g., in the form of individual records or aggregate reports) must adhere to the policies and regulations established by the organization, including procedures for protecting PII when sharing with other agencies and disclosure avoidance procedures for protecting PII from disclosure in public reports.
The EU GDPR[31], specifically Articles 5, 6, 25, and 32, sets a high standard for data protection, ensuring personal data is processed lawfully, transparently, and for a specified purpose. It enables data sharing and innovation while safeguarding individual privacy rights.
Ensuring Equitable and Secure Access to Digital Data
Equitable and secure access to digital data ensures all stakeholders can benefit from data resources. This requires robust security measures and equitable access protocols to prevent misuse and ensure widespread data benefits.
The Open Data Portal of Kenya[32], for example, provides access to datasets in agriculture, education, health, and more. By making this data publicly available, the initiative promotes transparency and innovation while protecting sensitive personal information through anonymization techniques.
Open Data vis-à-vis Privacy
Open data refers to datasets that are publicly accessible and free for anyone to use, modify, and share. Since it does not pose risks to privacy or security, open data is the least restricted in terms of usage. Governments, international organizations, and other entities typically make these non-sensitive datasets available to promote transparency, innovation, and public participation. For instance, government meteorological agencies, such as the National Oceanic and Atmospheric Administration (NOAA) in the United States, often release weather data to the public. Furthermore, national statistics bureaus like the Kenya National Bureau of Statistics provide demographic, economic, and social data on open data portals such as Kenya Open Data. Additionally, organizations such as the International Telecommunication Union (ITU) and the World Bank offer a wealth of valuable open data, ranging from global economic indicators to social development statistics. Moreover, academic institutions often make research data available to the public, contributing to scientific advancements and innovation.
Figure 2. Examples of open data
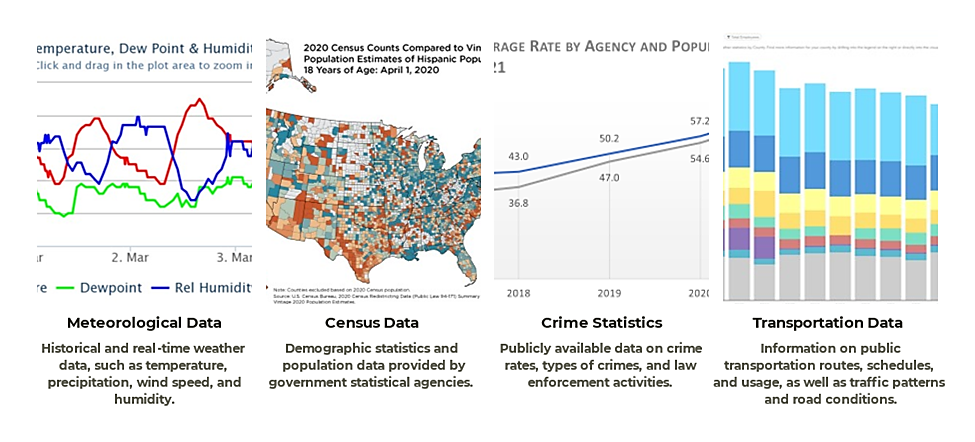
Source: Adapted from ITU (2021) Emerging technology trends: Artificial intelligence and big data for development 4.0, http://handle.itu.int/11.1002/pub/81886d62-en
Open data initiatives aim to make data freely available for everyone to use, fostering transparency, accountability, and innovation. By opening up datasets, governments and organizations can stimulate economic growth, enable scientific research, and improve public services. For instance, open access to traffic data can lead to better urban planning and reduced congestion, while open health data can accelerate medical research and public health interventions.
However, ensuring data protection and privacy is equally critical to protect individuals from harm, such as identity theft, discrimination, and unwarranted surveillance. Data protection and privacy involves securing personal data against unauthorized access and ensuring that individuals maintain control over their information. For example, personal health records need stringent privacy protections to prevent misuse and maintain trust in healthcare systems. Balancing between these objectives is crucial to harness the benefits of open data while safeguarding individual rights.
Achieving a balance between transparency and data privacy rights involves creating legal frameworks that support data openness while protecting personal data. The EU’s GDPR provides a comprehensive example of how to maintain high privacy standards while promoting data accessibility (see Box below). Another example is New York City’s Open Data Law, which mandates that all public data be available on a single web portal by 2018. The law ensures transparency and public access to government data while incorporating stringent privacy protections to prevent releasing sensitive personal information.[33]
EU GDPR The EU GDPR includes several provisions that establish a framework for balancing data accessibility and privacy protection. Key articles like Article 6, Article 25, and Article 32 are designed to enable lawful data processing while ensuring that privacy principles are upheld throughout data lifecycle management. Article 6: Lawfulness of Processing Article 6 provides the legal basis for processing personal data and specifies six grounds under which such processing is considered lawful. This article enables data controllers to use personal data in a variety of scenarios—such as obtaining consent, fulfilling contractual obligations, meeting legal requirements, or protecting the vital interests of individuals. This provision allows for data accessibility for legitimate purposes but ensures that data cannot be accessed or processed arbitrarily. By establishing a clear legal framework, Article 6 ensures that the use of personal data is subject to strict conditions that prevent misuse while enabling data to be accessible for specific, authorized purposes. Article 25: Data Protection by Design and by Default Article 25 mandates that data protection considerations must be incorporated into all stages of data processing activities, from design to implementation. This means that data accessibility features—such as user interfaces or data-sharing functionalities—must be designed with privacy in mind. For example, by implementing data minimization, default privacy settings, and purpose limitation, organizations can ensure that only the minimum necessary personal data is accessible and only for specific, intended purposes. Additionally, controllers must choose settings that protect data by default (e.g., ensuring data is not shared publicly without explicit consent). This provision ensures that the accessibility of data does not compromise privacy but instead upholds it as a foundational element of the system design. Article 32: Security of Processing Article 32 sets out security requirements for the processing of personal data, emphasizing the importance of implementing measures such as pseudonymization and encryption to protect data during storage and transmission. These techniques enable organizations to make data accessible while preserving privacy, as they prevent unauthorized access and make the data unintelligible to unauthorized parties. Additionally, this article requires organizations to maintain the confidentiality, integrity, availability, and resilience of their processing systems. This means that data can be accessible to authorized users when needed, while robust security measures protect against unauthorized access or breaches. Enabling Data Accessibility while Preserving Privacy Together, these articles create a cohesive framework where data accessibility is permitted only within the boundaries of lawful processing (Article 6), under conditions that ensure privacy by design (Article 25), and within a secure environment (Article 32). For example, by implementing privacy-preserving techniques like pseudonymization, organizations can share data for research or statistical purposes without revealing identifiable personal information, thus supporting data accessibility while protecting privacy. This regulatory approach ensures that data can be used for legitimate purposes without compromising the rights and freedoms of individuals, establishing a balance between data utility and privacy protection. |
Legal Frameworks Governing Openness and Privacy
Legal data protection frameworks, such as the European Union’s GDPR and the California Consumer Privacy Act (CCPA), have set the standards for data privacy and openness. These frameworks help regulators navigate the complexities of digital data governance, ensuring data sharing does not infringe on privacy rights. The Box below showcases additional data protection regulations/initiatives, which serve as examples of a successful balance of openness and privacy.
Case Studies Illustrating Successful Balance of Openness and Privacy
South Africa’s POPIA (Protection of Personal Information Act) promotes the protection of personal information processed by public and private bodies. Similar to the GDPR, it encourages the free flow of information while ensuring that personal data is protected. This law supports innovation in digital data use while safeguarding privacy.[34]
Brazil’s General Data Protection Law (LGPD) is modelled after the GDPR and sets out comprehensive rules for data processing. It aims to ensure privacy and protection of personal data while fostering transparency and enabling the free flow of information for innovation and economic growth.[35]
Digital India Initiative aims to ensure government services are made available to citizens electronically by improving online infrastructure and increasing Internet connectivity. The initiative balances openness and privacy by implementing robust data protection measures inspired by international standards like the GDPR.[36]
Estonia’s e-Residency Program offers citizens a secure digital identity, enabling them to access e-services like banking, education, and business registration. The program balances openness with stringent privacy measures, using advanced encryption and blockchain technology to ensure data security.[37]
Protection of Digital Data as an Intellectual Property Asset
Digital data as an IP asset requires careful management to protect its value. This involves establishing clear guidelines for data ownership, usage rights, and the protection of proprietary data. For instance, the Creative Commons licensing system provides a flexible range of protections and freedoms for authors, allowing them to retain certain rights while permitting others to use their work under specific conditions.[38] Additionally, the FAIR (Findable, Accessible, Interoperable, Reusable) data principles[39] encourage open data sharing while respecting intellectual property through proper attribution and licensing. These practices not only protect data creators and owners but also promote innovation and collaboration by ensuring that others can use data responsibly and ethically.
In collaborative environments, managing IP rights is crucial to ensure all parties benefit from shared digital data. This includes developing clear data-sharing agreements and licensing arrangements that respect the contributions of all stakeholders.
OpenStreetMap is a collaborative project aiming to create a free, editable map of the world. Contributors add and edit data under an open license, ensuring anyone can use and share the map. Clear data-sharing agreements and licensing arrangements protect contributors’ IP rights while promoting collaboration and innovation.[40]
Data Protection and Privacy
Personal data refers to any information that can specifically identify an individual, whether directly or through a combination of other data points. This includes obvious identifiers like names, social security numbers, and email addresses, as well as more nuanced data such as IP addresses, geolocation data, and cookies that can trace online behavior. For instance, in the healthcare sector, personal data includes patient records, medical histories, and genetic information, which must be handled with extreme care due to its sensitivity. In the marketing industry, personal data such as purchase history and browsing habits allows companies to target consumers with personalized ads. However, due to its potential to expose intimate details about an individual’s life, the collection, processing, and transfer of personal data are heavily regulated by data protection laws, which enforce stringent requirements to ensure that individuals’ privacy rights are protected, mandating explicit consent for data use and granting individuals the right to access, correct, or delete their data (see section below on key data protection principles). Unlike non-personal data (see below), personal data requires strict oversight and robust security measures to prevent unauthorized access, misuse, or breaches that could lead to significant harm to individuals’ privacy and well-being.[41]
Non-Personal Data: Non-personal data, also known as non-personally identifiable information, encompasses a wide range of information that does not identify specific individuals. This can include aggregated data such as anonymous datasets and various other data types that cannot be linked back to any particular person. Examples of non-personal data include industrial data like production statistics, supply chain information, and machinery performance metrics utilized in the industrial and manufacturing sectors. Another example is traffic patterns, which encompass data on vehicle flows, congestion levels, and public transportation usage. For instance, many cities rely on traffic pattern data to manage urban planning and transportation systems effectively. Non-personal data does not identify specific individuals and includes aggregated or anonymized information. This category is critical because it fuels industrial processes, analytics, and other sectors without posing privacy concerns. Regulating this data is essential for enabling digital economy growth, allowing cross-border data flows while ensuring it is not misused to re-identify individuals.
Many governments around the globe have started regulating the status and transfer of non-personal data to enable the thriving and growth of the digital economy. For instance, the European Union Regulation on the Free Flow of Non-Personal Data ensures and permits the free flow of non-personal data across national boundaries. Both regulators and private sector organizations should have simple access to this kind of data. The GDPR, on the other hand, governs the security and protection of personal data.[42]
Figure 3. Examples of non-personal data
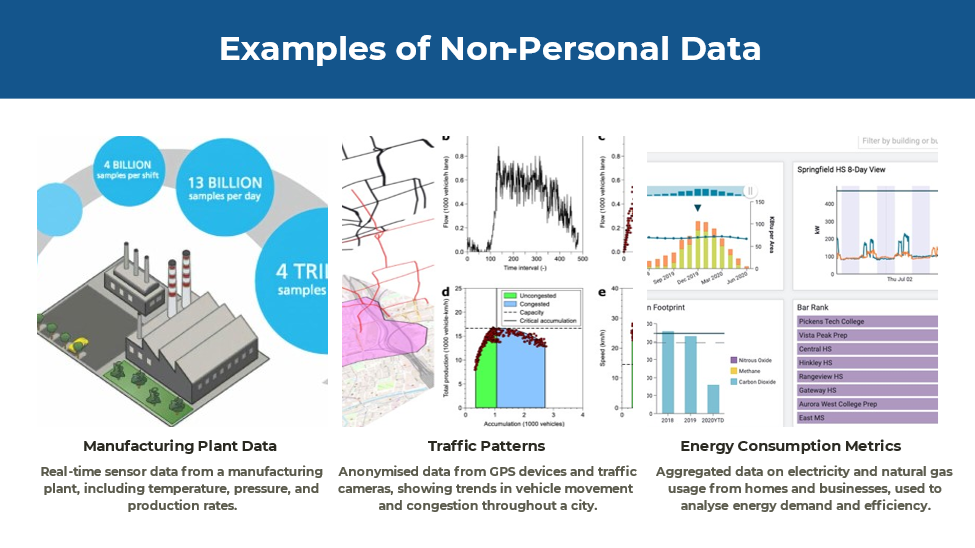
Source: Adapted from India’s Non-Personal Data Governance Framework, https://prsindia.org/policy/report-summaries/non-personal-data-governance-framework
Key data protection principles
Data protection necessitates a comprehensive approach to system design, integrating legal, administrative, and technical measures. Numerous countries have enacted general data protection and privacy laws applicable to government and private-sector activities involving the processing of personal data. Aligning with international privacy and data protection standards, these laws generally include broad provisions and principles[43] related to the collection, storage, and use of personal information:
Use and collection limitation and purpose specification
Personal data should only be collected and used for reasons permitted by law and hence should, in theory, be known to the data subject at the time of collection; or for reasons that the data subject has authorized. This means that entities that collect data (data collectors) should:
- clarify why they are collecting personal data and what they intend to do with it from the beginning;
- comply with documentation responsibilities to specify the purpose of data collection;
- comply with transparency responsibilities to inform individuals about the purpose of data collection; and
- ensure that if they plan on using personal data for any purpose additional to or different from the originally specified purpose, the new use is fair, lawful, and transparent.[44]
An example of a new use of data that is not fair, lawful, or transparent is: A doctor gives his wife’s travel agency access to his patient list so she may provide recuperating patients with special vacation offers. It would be inconsistent with the reasons for which the information was gathered to disclose it for this purpose.[45]
Proportionality and minimization: To avoid unnecessary data collection, the data collected must be proportionate to the purpose. This is often articulated as requiring that only the “minimum necessary” data, transaction metadata included, should be collected to fulfill the intended purpose.[46]
Lawfulness, fairness, and transparency: Personal data should only be collected, stored, and used on a lawful basis based on specific grounds such as consent, contractual necessity, legal compliance, protection of public interest, or legitimate interest. Fair and transparent procedures should be followed when collecting and using personal data.[47]
- Lawfulness: In many jurisdictions, additional conditions apply to processing sensitive data types, such as health and medical records.
For instance, in the healthcare sector, a hospital processing patient records without explicit consent may face severe legal consequences.
Similarly, if processing data involves committing a criminal offense, it will be unlawful. Imagine a scenario where a company unlawfully accesses and processes copyrighted material for commercial gain; the company would violate intellectual property laws, but not necessarily data protection laws, unless the material also contained personal data.
Processing may also be unlawful if it results in privacy violation and discrimination. For example, surveillance data used to discriminate against minority groups would constitute a breach of privacy. If data has been processed unlawfully, data protection laws grant data subjects the right to erase that data or restrict its processing, ensuring their privacy and data protection rights are upheld.[48]
- Fairness: If any aspect of data processing is unfair, the data controller will be in breach of this principle, even if they can show that they had a lawful basis for the processing. Fairness means that data controllers should only handle personal data in ways that people would reasonably expect and not use it in ways that have unjustified adverse effects on them.
For instance, if a social media platform collects user data under the guise of improving user experience but sells this data to third parties for targeted advertising without users’ consent, this practice would be deemed unfair.
Whether information is processed fairly depends partly on how it was obtained. If the person was deceived or misled when the personal data was obtained, then this use and processing of data are unfair.
For example, if a website tricks users into signing up for a newsletter by hiding the opt-out option, this is unfair processing. This also requires assessing how this impacts the interests of the people concerned – collectively and individually. If data has been obtained and used/processed fairly in relation to most people it relates to but unfairly in relation to only one individual, this use will be unfair. An example of this could be a workplace monitoring system that fairly tracks employee performance but unjustly targets a single employee for invasive surveillance.[49]
- Transparency: Transparency is intrinsically tied to fairness. Transparent processing entails being upfront, explicit, and honest with individuals about how and why their personal data will be utilized, and for what purpose.
For example, an online retailer should clearly inform customers that their purchase history will be used to recommend products, rather than providing this information in the fine print. Transparency is always essential, especially when individuals have the option of whether to engage in a relationship with the institution seeking to gather their data. Imagine a mobile app that transparently explains it will access location data to provide localized services; users can then make an informed decision about whether to download the app.
Transparency is even more important in cases of so-called “invisible processing” – where individuals have no direct relationship with the processing entity that has collected their personal data from another source.
For example, data brokers often collect personal information from various sources without individuals’ knowledge, making transparency crucial in such cases. Data subjects should be told about data processing in a way easily accessible and easy to understand, using clear and plain language. For instance, a bank should use simple terms to explain its data usage policies on its website, ensuring that all customers can understand how their data will be used and protected.[50]
Accuracy and data quality: Personal data must be accurate and current, with any errors promptly corrected.[51] Every possible measure must be made to ensure that inaccurate personal data is immediately deleted or corrected, taking into account the purposes for which they are collected.[52]
Storage limitations: Personal data, including transaction metadata, should only be retained for as long as necessary to fulfil the purposes for which it was collected and processed. For transaction metadata, individuals should have the option to determine the duration of data retention. For instance, the United Kingdom’s GDPR permits the retention of personal data for extended periods if it is solely for public interest archiving, scientific or historical research, or statistical purposes. This is contingent on implementing the necessary technical and organizational safeguards to protect individuals’ rights and freedoms as mandated by the GDPR.[53]
Consider a financial institution that collects transaction metadata from its customers. This data should only be retained for the duration necessary to complete and verify transactions. However, customers could be given the option to specify how long their transaction metadata is stored, perhaps opting for shorter retention periods to enhance their privacy.
Another example is in medical research. A hospital might retain patient data for extended periods to support long-term studies on public health trends. As long as the data is anonymized and strict security measures are in place, this practice aligns with GDPR provisions, ensuring the data is used ethically and responsibly while protecting patient confidentiality.[54]
Privacy-enhancing technologies (PETs):
Data controllers should implement advanced technical and organizational safeguards to prevent the unauthorized or unlawful processing of personal data and mitigate the risks of accidental loss, destruction, or alteration. For example, organizations can use tokenization techniques[55] to replace sensitive data, such as Social Security Numbers, with unique non-sensitive tokens that are meaningless outside the system. This ensures that even if the data is accessed by unauthorized parties, it remains unusable.
Additionally, data controllers should employ differential privacy[56] when processing large datasets. This technique introduces statistical noise to the data, allowing for valuable insights while maintaining individual privacy by making it difficult to identify any single individual’s information.
To further protect personal data, organizations should implement zero-knowledge proofs[57], which enable data verification without revealing the underlying information. For instance, when verifying a person’s age for access to restricted content, a zero-knowledge proof can confirm that the user is over 18 without disclosing their exact birthdate.
Data minimization should also be prioritized by employing privacy-first architectures, such as federated learning[58], which enables AI learning models to be trained on decentralized data sources without transferring raw data to a central server. This prevents excessive data collection and supports compliance with principles like purpose limitation under data protection regulations.
These measures, combined with regular audits and automated compliance checks, can help ensure that personal data is handled in a secure and compliant manner, safeguarding against breaches and unauthorized access while maintaining compliance with global data protection standards.[59]
Accountability: Personal data processing should be supervised by an authorized, independent monitoring authority as well as by the data subjects themselves. Accountability should be at the heart of any legislation governing the processing of personal data and the preservation of persons’ rights, and a regulator or authority must thus implement data protection regulations. The extent to which these authorities are empowered varies by country, as does their independence from the government.
Some countries, such as Colombia, have established more than one regulatory agency for monitoring, regulation, and enforcement of data protection regulations, with varying authorities depending on whether public or private enterprises handle the data. These powers may include the capacity to conduct investigations, respond to complaints, and levy fines when an entity violates the law.[60] According to Law 1266, there are two different authorities on data protection and privacy matters. The first of them, which acts as a general authority, is the Superintendent of Industry and Commerce (SIC). The second authority is the Superintendence of Finance (SOF), which supervises financial institutions, credit bureaus, and other entities that manage financial data or credit records and verifies the enforcement of Law 1266. Nevertheless, under Law 1581, the SIC is the highest personal data protection and privacy authority. It is empowered to investigate and impose penalties on companies for the inappropriate collection, storage, usage, transfer, and elimination of personal data.[61]
Data Subjects, Controllers and Processors
Many data protection laws differentiate between the following categories of data stakeholders: data subjects, data controllers, and data processors. The table below gives an overview of detailed functions in personal data ownership and governance.
Functions in data ownership
|
Data Subjects |
|
|
Data Controllers |
|
|
Data Processors |
|
Data Controllers: examples ICT Regulatory Authority: A national ICT regulatory authority collects and processes data from telecom operators to monitor compliance with industry standards and regulations. This data includes performance metrics, service quality reports, and customer complaint logs. The regulatory authority decides how this data is collected, processed, and used to ensure compliance with telecom regulations. It is responsible for the security and integrity of the data, ensuring it is stored and processed in accordance with data protection laws and ensuring transparency with stakeholders about data usage. Network Operators/Service Providers: A network operator/service provider collects data directly from its subscribers, including personal information, billing details, and usage patterns. This data is used to manage customer accounts, provide services, and improve network performance. As the data controller, the operator must ensure that all collected data is handled in compliance with data protection regulations. This includes informing customers about data collection practices, obtaining necessary consent, and implementing security measures to protect data from breaches. The operator must also manage data retention policies and ensure that data is only used for the purposes specified to customers. Data Processors: examples Data Analytics Firms: A telecom company contracts a data analytics firm to process customer usage data. The firm analyses patterns in data usage, call durations, and internet consumption to provide insights that help the telecom company optimize its services and pricing models. The data analytics firm must process data in compliance with the telecom company’s instructions and relevant data protection regulations. They must ensure data is anonymized where necessary to protect customer identities and use robust security measures to prevent unauthorized access during processing. Customer Support Services: A telecom provider outsources its customer support services to an external company. The customer support company processes personal data, such as contact details and service histories, to assist customers with their inquiries and issues. The customer support service must handle data securely, only using it for the intended purpose of customer support. They need to follow the telecom provider’s data handling protocols and ensure compliance with data protection laws to safeguard customer privacy. Source: https://www.digitalguardian.com/blog/data-controller-vs-data-processor-whats-difference; https://www.datagrail.io/blog/data-privacy/the-difference-between-data-controllers-and-data-processors/ |
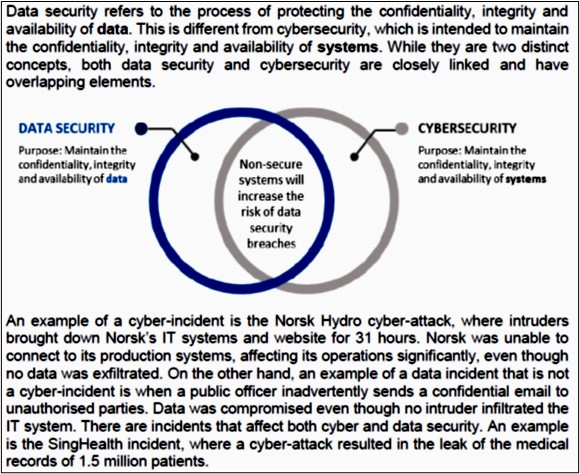
Data Security
Data Security is a component of data governance that addresses the need to safeguard data from unauthorized access, breaches, and other security threats. It involves establishing security policies, access controls, encryption, and other protective measures to ensure that data remains confidential and secure. Compliance with privacy and data protection regulations is also a key aspect of this component.
Data security and risk management: Ensuring the security of sensitive data (i.e., data that carry the risk for harm from an unauthorized or inadvertent disclosure) and personally identifiable information (PII) by defending against the risks of unauthorized disclosure is a top priority for an effective data governance program. This goal is achieved by establishing a comprehensive data security management plan with a system of checks and controls to mitigate data security risks. The policies and guidelines should specify rules for work-related and personal use of all organizational computer and data systems, including procedures for data use, assessing data risks to identify vulnerabilities, and handling data security breaches; and explain how compliance with these policies is monitored. It is critical to conduct regular staff trainings and audits to ensure compliance with organizational policies and procedures. The data security and confidentiality plan should be regularly reviewed and modified to stay up-to-date on the latest threats.
Source: https://www.mddi.gov.sg/gov-personal-data-protection-laws-and-policies
Data security and cybersecurity regulations go hand in hand, as they both pertain to protecting data stored digitally or in the cloud. However, as shown in the box above, there is a difference between them. Many data protection and cybersecurity laws require that personal information be stored and processed securely and guarded against unauthorized or unlawful processing, loss, theft, destruction, or damage.
Typical data security precautions that a national legal framework could require are the following:
- Personal data encryption
- Personal data anonymization
- Personal data pseudonymization
- Confidentiality of data and systems that use or generate personal data
- Integrity of data and systems that use or generate personal data
- The capacity to recover systems that use or generate personal data following a technical or physical incident
- Data breach notification reporting timelines
- Continuous testing, evaluation, and assessment of the security of systems that use or generate personal data[62]
In addition, many international standards require data controllers to notify data subjects of severe data breaches impacting their personal information. Countries may also have laws that regulate the identification and mitigation of cyberthreats and penalize unlawful data access, use, or modification. Lastly, regulatory frameworks should provide enough sanctions for unlawful access, use, or modification of personal data by data administrators and third parties.[63]
Incorporating “Privacy by Design” and “Security by Design” principles is important for building and maintaining responsible, robust, and compliant data governance practices. It means that privacy and security considerations are embedded into every stage of the data lifecycle (refer to the section on Data Lifecycle below), from initial collection to final disposal.
Privacy by Design[64] involves anticipating and preventing privacy-invasive events before they happen. For example, when developing a new customer database, organizations should:
- Minimize data collection to only what is necessary.
- Implement data anonymization techniques to protect personal identities.
- Ensure data is encrypted in transit and at rest.
- Design systems that allow users to control their data, providing options for consent and data access requests.
An example of “Privacy by Design” in practice is the development of mobile applications that only request access to necessary user data and provide clear, easily accessible privacy settings for users to manage their data permissions.
Security by Design[65] makes sure that security measures are integrated into the system architecture from the outset. For example, in the development of a cloud-based service, organizations should:
- Establish strong access controls to limit data access to authorized personnel.
- Conduct regular security assessments and penetration testing.
- Deploy intrusion detection systems to monitor and respond to potential threats.
- Design redundancy and recovery processes to maintain data integrity and availability in case of an incident.
An example of “Security by Design” in practice is multi-factor authentication (MFA) for accessing sensitive data systems, ensuring that even if one security layer is compromised, additional barriers are in place to protect the data.
Transformative Technologies and Data Governance
Transformative technologies such as AI, IoT, and blockchain present new challenges and opportunities for data governance. This section examines the impact of these technologies, focusing on their role in data governance, ethical and legal aspects and challenges, and the need for transparency and accountability.
Impact of AI on data governance
Artificial Intelligence (AI) refers to the ability of machines, especially computers, to perform tasks that typically require human intelligence.64
In the world of AI, data is often referred to as the “fuel” that powers these advanced systems. Just as a car cannot run without fuel, AI systems cannot function effectively without data. The reason for this analogy lies in how AI systems operate: they rely on vast amounts of data to learn, adapt, and make decisions.
- AI systems, particularly those based on machine learning, require extensive training datasets. During this training phase, AI models are fed large quantities of data to recognize patterns, make predictions, and improve their accuracy over time. The more data an AI model is exposed to, the better it can learn and make decisions. For instance, in image recognition, an AI model needs to analyze thousands, if not millions, of images to identify objects accurately.
- The quality and quantity of data directly impact the accuracy of AI systems. High-quality, diverse datasets enable AI models to perform better by covering various scenarios and reducing biases. Conversely, poor-quality or insufficient data can lead to inaccurate predictions and flawed outcomes, underscoring the critical role that data plays in the success of AI applications.
- AI systems often need to make decisions in real-time, particularly in dynamic environments like autonomous vehicles or financial trading systems. In these cases, AI relies on continuous streams of data to make instantaneous decisions. This real-time data acts as a constant source of information that keeps the AI system updated and responsive to changes in its environment.
- Data also enables AI to provide personalized experiences, tailoring services or products to individual preferences. For example, recommendation engines used by streaming services like or e-commerce platforms analyze user data to suggest content or products that align with the user’s interests. Without access to user data, these systems would be unable to offer such personalized recommendations.
- The availability of diverse and expansive datasets spurs research and innovation in AI. Researchers and developers can use data to experiment with new algorithms, test different hypotheses, and push the boundaries of what AI systems can achieve. This continuous cycle of data-driven experimentation leads to advancements in AI capabilities and the development of new applications across industries.
- When it comes to data governance, AI plays a critical role. On the one hand, AI tools can help enforce data governance by automatically organizing, monitoring, and protecting data. They can also assist in ensuring that data is used in ways that comply with regulations and policies. For example, AI can help identify and flag data that might be sensitive or at risk of being misused, making it easier for organizations to manage their data responsibly. [66]
While data is crucial for AI, managing this data poses several challenges:
- AI facilitates the collection, processing, and reuse of massive quantities of data and images. This can impact data protection rights enjoyed by data subjects. For instance, social media companies rely on the automated collection and monetization of vast quantities of Internet user data. Data brokers collect, combine, analyze, and distribute personal information to various recipients. Existing data protection regulatory frameworks around the world impose minor restrictions on these data exchanges, mainly insulated from public scrutiny. The generated data sets are extensive, and the acquired information is of unparalleled scope. 65
- This has had severe implications for enjoying the right to privacy. AI technologies are increasingly employed in online tracking and profiling, where individuals’ browsing habits are collected through “cookies” and digital fingerprinting. This data is then combined with queries made via search engines or virtual assistants. Mobile apps further process behavioral data (e.g., location and health information) from smart devices. For instance, targeted advertising utilizes internet tracking and AI profiling to predict and cater to the interests of Internet users online. Social media algorithms decide the content of a user’s newsfeed and influence the number of people who see and share information. Search engine algorithms index content and determine what appears at the top of search results. The automated nature of these processes has made it nearly impossible for users to provide informed consent, as required by many data protection laws. These practices raise significant privacy and data protection concerns for regulators.66
- The pervasive use of AI in data processing can threaten the right to privacy and exacerbate other rights violations. Personal data can be misused to target individuals in contexts such as insurance or employment applications, where algorithmic decisions may unfairly disadvantage certain demographic groups. 67 For instance, algorithms used in hiring processes might inadvertently discriminate against candidates from marginalized communities, perpetuating existing biases and inequalities. AI tools are used to look for patterns in human behavior; they can be used to make inferences about everyday things that are deeply private and personal, such as how many residents of a neighborhood are likely to visit a specific place of worship, what television programs they might enjoy, and even roughly their sleeping patterns. The use of AI techniques can identify groups, such as those who share a specific political or personal stance, and draw broad conclusions about individuals, including about their mental and physical health. As AI can often serve as the foundation for decisions that have an impact on people’s rights68, many countries worldwide recognize data protection as a fundamental right (see, for example, Article 8 of the European Convention on Human Rights—ECHR).69
- Creating new data is a unique challenge in the automated processing of personal data. It is often possible for personal data to be combined by using AI tools, leading to the creation of second and even third generations of data about a particular person. When compared to a much bigger data set, two seemingly unrelated pieces of information might “breed” and produce new data, unbeknownst to the data subject. Significant questions are raised regarding the concepts of consent, openness, and personal autonomy.71
- For AI to be effective, the data must be accurate, complete, and relevant, as poor-quality data can lead to incorrect AI outputs, which can have serious consequences in critical applications like healthcare or autonomous driving. [67]
With AI systems consuming and processing vast amounts of data, robust data governance frameworks are necessary to ensure that data is used ethically and in compliance with legal standards.
Profiling people through AI In 2018, the Italian Data Protection Authority (Garante) identified a violation of the national data protection law by a data controller offering personalized rates to car-sharing service customers based on their observed habits and characteristics. During the administrative procedure, the defendant argued there was no “categorization” of users since the information used to determine fees was not directly linked to the data subjects. The DPA dismissed these objections, concluding that personal data processing had occurred, that it was exclusively automated, and that it aimed to profile individuals or analyze their habits or consumption choices. In 2021, the Italian Supreme Court (Corte Suprema di Cassazione) upheld this decision, resulting in an administrative fine of €60,000. The Court ruled that processing personal data using an algorithm to determine individual rates constitutes profiling, even if the controller does not store the data or the data is not directly attributable to the data subject. Source: Stankovich M et al., UNESCO (2023) Global Toolkit on AI and the Rule of Law for the Judiciary Anonymization does not equal privacy Data privacy is commonly protected through anonymization, which involves removing identifiable information such as names, phone numbers, and email addresses. Data sets are modified to be less precise, and “noise” is introduced to obscure specific details. However, a study published in Nature Communications suggests that anonymization does not always guarantee privacy. Researchers have developed a machine learning (ML) model capable of re-identifying individuals from an anonymized data set by using their postcode, gender, and date of birth. |
These examples highlight the urgent need for regulators to ensure that AI applications are developed and deployed responsibly. Stricter oversight and robust regulatory frameworks are essential to safeguard individual rights and promote transparency in data processing activities.70
In the context of AI and data governance, several critical issues warrant further attention. One pressing concern is the extent of control that individuals will have over the information collected about them. Given their significant role in providing personal data for machine learning (ML) training purposes, there is a growing debate about whether individuals should have the right to utilize the resulting AI models or at least be informed about how their data is being used. Additionally, there are privacy implications to consider, such as the potential for data-seeking AI systems to violate privacy rights inadvertently. For example, analyzing the genome of one family member could reveal sensitive health information about other family members, raising ethical questions about consent and data usage. 72
Data Protection Impact Assessments
When sourcing and processing data for AI development, it is crucial for developers to evaluate whether a Data Protection Impact Assessment (DPIA) is required. This involves assessing the potential risks associated with personal data processing and ensuring that the data collected for analytics is used strictly in accordance with its intended purpose. Developers must also confirm that no data has been improperly disclosed during the collection or processing phases.[68]
Personal data should only be collected in accordance with the organization’s established privacy and data protection policies and the legal and regulatory requirements specific to the country in which the organization operates. During the data processing phase, particular attention should be paid to the datasets used in model development. It is essential to review these datasets to minimize the inclusion of potentially sensitive or personal data, thereby reducing the risk of privacy breaches.[69]
Data Protection Issues in AI Relevant to Developing Countries AI poses significant data protection challenges, particularly due to algorithmic opacity—the difficulty in understanding how an algorithm uses, collects, or modifies data. This opacity may result from the complexity of the algorithm or the use of trade secrets. For regulators in developing countries, this makes it challenging to oversee how data are transformed into decisions, hindering effective regulation. Data repurposing is a key concern, where data collected for one purpose are later used for another without proper consent. For example, in countries with growing digital health initiatives, data collected for managing a vaccination campaign might be repurposed by private insurers to determine an individual’s eligibility for life insurance. Or, consider the case of a health app that tracks a user’s location and daily habits to provide fitness recommendations. While beneficial, this data could be repurposed by insurance companies to adjust premiums based on perceived risk factors, often without the data subject’s explicit knowledge or consent. This is particularly concerning in regions where digital health records are just beginning to be integrated into broader health systems. Data spillovers occur when data are unintentionally collected on individuals who were not meant to be included. A specific example could involve AI-driven surveillance systems in urban areas, where video data meant for traffic monitoring might also capture and analyze the activities of passers-by without their consent. In countries where urbanization is accelerating, such spillovers can lead to widespread data protection concerns. Data persistence refers to data remaining in use long after they were collected, often beyond what was initially anticipated. In regions where digital infrastructure is developing, the lack of established data deletion practices means that data collected for temporary purposes, like tracking disaster relief efforts, might be stored and used indefinitely. This can become problematic as individuals’ data protection preferences evolve, yet their data continues to be used without updated consent. |
Where feasible, anonymized data should be employed, provided that its use does not compromise the quality or effectiveness of the AI model. Anonymization helps mitigate the risk of identifying individuals, ensuring that the privacy of data subjects is maintained. If developers and deployers obtain personal data from third-party sources, it is imperative to conduct thorough due diligence. This due diligence process should verify that the third party is authorized to collect and disclose personal data on behalf of individuals or that the third party has obtained the necessary consent to disclose such data. This step ensures compliance with data protection regulations and helps prevent the unauthorized use of personal data.
Checklist for Data Protection Impact Assessment (DPIA):
| ☑ Identify the Need for a DPIA: |
|
| ☑ Describe the Data Processing: |
|
| ☑ Assess Necessity and Proportionality: |
|
| ☑ Identify and Assess Risks: |
|
| ☑ Implement Measures to Mitigate Risks: |
|
| ☑ Consultation: |
|
| ☑ Document the DPIA: |
|
| ☑ Review and Update DPIA: |
|
| ☑ Monitor Data Processing: |
|
| ☑ Ensure Compliance: |
|
Impact of IoT on Data Governance
The Internet of Things (IoT) significantly impacts data governance due to its extensive data generation capabilities. IoT devices, ranging from smart home appliances to industrial sensors, continuously collect vast amounts of data. For example, smart city initiatives utilize IoT sensors to monitor traffic, air quality, and energy consumption, generating data to optimize urban management and enhance residents’ quality of life.[71]
However, the proliferation of IoT devices raises substantial privacy and security concerns. These devices often collect sensitive personal information without explicit user consent, leading to potential misuse and data breaches. The 2016 Mirai botnet attack, which compromised numerous IoT devices, underscored the vulnerabilities and security risks associated with IoT data.[72] Data protection regulations worldwide aim to address these issues by imposing stringent data protection requirements on IoT data collection and processing.
Moreover, IoT data governance requires transparency and accountability in data handling practices. Organizations must ensure that IoT data is collected, stored, and processed securely, with clear policies on data sharing and user consent. The challenge for regulators is to create flexible yet robust frameworks that can adapt to the rapid evolution of IoT technologies while safeguarding individuals’ privacy and rights.
Impact of Blockchain on Data Governance
Blockchain technology, known for its decentralized and immutable ledger system, presents unique challenges and opportunities for data governance. Blockchain’s core feature of immutability ensures that once data is recorded, it cannot be altered or deleted. This characteristic enhances data integrity and transparency, as seen in applications like supply chain management, where blockchain tracks and verifies the authenticity of products from origin to consumer.[73]
However, blockchain’s immutability also poses challenges for data governance, particularly concerning data privacy and the right to be forgotten. For instance, the European Union’s GDPR mandates that individuals have the right to request the deletion of their personal data. Implementing this requirement on blockchain platforms is complex due to the permanent nature of recorded transactions. Innovative solutions such as “off-chain” storage and privacy-preserving techniques like zero-knowledge proofs are being explored to reconcile blockchain’s benefits with regulatory compliance.[74]
Furthermore, blockchain’s decentralized nature requires new approaches to regulatory oversight. Blockchain’s decentralized and distributed nature can create compatibility issues with existing data protection frameworks. Traditional data privacy regulations often rely on the concept of centralized data controllers and processors, whereas blockchain operates without a central authority. This can make it difficult to determine who is responsible for protecting the data and ensuring compliance with privacy regulations. The decentralized nature of blockchain also raises questions about how to manage data privacy effectively in a system where data is spread across multiple nodes.
Thus, traditional centralized governance models may not be applicable, necessitating the development of decentralized governance frameworks. Projects like Ethereum and Hyperledger are experimenting with governance models that involve multiple stakeholders in decision-making processes, aiming to balance transparency, security, and user autonomy.
|
Regulatory Approaches to Managing AI-Related Data Issues Regulators worldwide are adopting various approaches to manage AI-related data issues. For instance, the EU has the AI Act[75], a comprehensive regulatory framework that categorizes AI systems based on their risk levels and imposes corresponding regulatory requirements. High-risk AI systems, such as those used in healthcare and law enforcement, are subject to stringent oversight, including mandatory risk assessments and transparency obligations. The EU AI Act has introduced substantial revisions to data protection practices, such as: Complementing the GDPR: The AI Act operates in conjunction with the GDPR, emphasizing the safe development and deployment of AI systems while safeguarding personal data. Collectively, they establish a comprehensive data protection framework. Privacy by Design and Default: AI systems must embed privacy measures from the outset and throughout their entire lifecycle, ensuring that data protection is an inherent feature. For example, when developing an AI system for monitoring public health, privacy safeguards would be built into the system from the beginning, ensuring that all health data is automatically protected. Data Minimization and Anonymization: AI systems are required to process only the minimum necessary personal data. Whenever feasible, data should be anonymized to protect individuals’ privacy. A relevant example would be an AI-driven education platform that only collects and uses students’ essential information, anonymizing data to protect their identities. Transparency and Accountability: AI developers must be transparent regarding how personal data is utilized, with thorough documentation and accountability protocols in place to ensure data protection. For instance, a company developing an AI tool for financial services would need to clearly document how customer data is being used and ensure that there are accountability measures in place for any data handling issues. Enhanced Security Protocols: The Act highlights the necessity for robust security measures, such as encryption, to protect personal data from unauthorized access and breaches. For example, an AI-based digital identity system would be required to use strong encryption to secure citizens’ data against potential cyber threats. In the United States, the National Institute of Standards and Technology (NIST) has developed a framework for managing AI risks[76], emphasizing the importance of transparency, fairness, and accountability. The framework provides guidelines for organizations to evaluate and mitigate the risks associated with AI systems, promoting ethical AI development and deployment. International collaboration is also crucial in addressing AI-related data governance challenges. Initiatives like the Global Partnership on AI (GPAI)[77] bring together governments, industry, and academia to develop best practices and policy recommendations for AI governance, fostering a coordinated approach to managing AI’s global impact. |
Cross-Border Data Flows
In a globalized world, data often crosses national borders, raising unique regulatory challenges. This section addresses issues related to international data transfers, exploring regulatory approaches to cross-border data flows and ensuring data protection in transnational contexts. It will also provide a checklist to guide regulators in managing cross-border data governance effectively.
| Mass amounts of data, such as those used by large private companies and governments, may require data centers consisting of hardware and software to store, protect, and back up data. Governments and public institutions are often responsible for managing confidential and sensitive data, and a key element of responsible data governance is protecting that data, which may include investing in advanced data storage and backup facilities. This, in turn, impacts data localization requirements. |
Data localization requirements and restrictions on cross-border data transfers are two main types of cross-border data movement measures. In general, there are six types of national data protection systems classified by the OECD according to their level of restrictiveness to data movement[78] (see Figure 4).
- The first type of approach, category 0, relates to the absence of any regulation on data flows. While data may flow out unimpeded, concerns about the absence of provisions on cross-border transfers may affect other entities or countries’ willingness to send data, affecting data transfers from certain countries.
- The second type of approach – “free-flow,” category 1, does not prohibit the cross-border transfer of data nor require any specific conditions to be fulfilled to move data across borders. This approach provides for ex-post accountability for the data exporter if the personal data sent abroad is misused.
- The “flow conditional on safeguard” group of approaches includes categories 2, 3, and 4, based on the principles of adequacy or equivalence as a condition for data transfers across borders. Each subgroup within this approach differs either in how adequacy or equivalence is applied, by whom, and the other options available for transfers in the absence of an adequacy assessment. Entities operating the transfer are subject to progressively more requirements about the steps they need to take before transferring data. Hence, entities operating in these countries face broader liability.
- The least flexible approaches fall under the “flow conditional, including on ad-hoc authorization” category. Under this category (5), the transfer depends on an adequacy finding by the relevant public authority or, where this is not granted, an ad-hoc approval by the relevant authority – which does not always have to be the data protection authority.
- Category six does not foresee the possibility of an adequacy finding that would automatically ensure the flow of data toward a third country. It requires that all transfers be subject to review by a relevant authority.[79]
Figure 4. Types of national data protection systems by the level of data restrictiveness
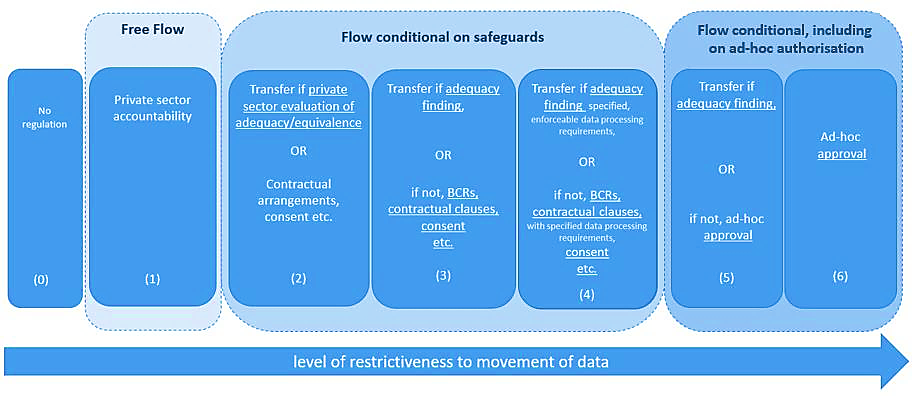
Source: OECD (2019) Trade and cross-border data flows
Regulation related to local storage requirements
Local storage requirements often target specific types of data. Local storage regulations, which may be accompanied by local processing requirements, can be aimed at personal data (vis-à-vis non-personal data, such as data on temperature levels, weather conditions data, etc.) or can be sectoral, typically targeting heavily regulated sectors such as health, telecoms, banking or payment processing, insurance, or satellite mapping. Some approaches combine storage requirements with flow and processing restrictions.[80]
Too restrictive data regulation affects where data is used, moved, or stored and where individual employees and contractors are located. Data localization and local data storage requirements can impede companies’ ability to transfer data needed for day-to-day activities, such as human resources data, which means companies may have to pay for redundant services. Also, companies may be compelled to spend more on compliance activities, such as hiring a data protection officer or installing software systems to get individuals’ or the government’s approval to transfer data. These additional costs are either borne by the customer or the firm, which can undermine competitiveness by cutting into profit margins. Alternatives to restrictive data transfer requirements, can be found in innovative mechanisms for data sharing (see section below on Innovative Approaches to Data Governance) that would protect data privacy.[81]
Public Trust, Engagement and Capacity Building in Data Governance
Building and maintaining public trust in data governance practices is essential for their success. Ensuring that data governance processes are open and transparent allows the public to understand how their data is being used and protected. The e-Estonia initiative[82], for example, provides citizens with access to their data and logs of who has accessed it, fostering a culture of transparency and trust. Additionally, the OECD Guidelines on the Protection of Privacy and Transborder Flows of Personal Data emphasize transparency as a core principle, encouraging member countries to adopt practices that promote openness and accountability in data handling.
Clear accountability mechanisms must be in place to handle data responsibly. This involves identifying responsible parties and establishing clear guidelines for data management. The EU’s GDPR sets a high standard for accountability by requiring organizations to implement data protection measures and document their data processing activities. Organizations must appoint Data Protection Officers (DPOs) to oversee compliance and ensure data is handled ethically and lawfully.
Involving the public in decision-making processes enhances trust and ensures that data governance practices align with public expectations and needs. The United Kingdom’s National Data Strategy includes public consultations to gather input from citizens and stakeholders, ensuring that data policies reflect the interests and concerns of the public. The United Nations’ “Building Trust in Data: Towards Fair and Equitable Data Governance” report also underscores the importance of public involvement in creating equitable data governance frameworks.
|
New Zealand’s Data Futures Partnership[83] is a collaborative initiative that brings together government, industry, and civil society to co-create data governance policies. This inclusive approach ensures that diverse perspectives are considered. Canada’s Digital Charter includes public consultations to shape its data governance policies, reflecting the collective input of its citizens.[84] Singapore’s Personal Data Protection Commission (PDPC) runs public awareness campaigns to educate citizens on data protection rights and responsibilities. These campaigns help demystify data governance and empower individuals to take control of their personal data.[85] |
Communicating the Benefits and Safeguards of Data Governance
Clear Communication is essential to use clear, non-technical language to explain data governance benefits and safeguards to the public. Providing educational materials and resources to the public enhances their understanding of data governance and its importance. Engaging with media to disseminate information widely further ensures that accurate and relevant information reaches a broad audience. In the United States, the NIST collaborates with media to promote awareness of its data governance frameworks and standards.
Collaboration between various regulatory agencies and sectors
Inter-agency and cross-sector collaboration is essential to address the complex and multifaceted challenges inherent in data governance. Mechanisms for effective coordination include joint task forces, shared databases, and regular inter-agency meetings. Successful collaborations, such as the European Data Protection Board’s harmonized GDPR enforcement[86] and the UK’s National Cyber Security Centre[87] working with ICT regulators on cybersecurity standards, and illustrating best practices. Recommendations for fostering cooperative governance include establishing clear communication channels, setting mutual objectives, and leveraging technology for seamless information sharing.
Collaborating with Academic and Industry Partners for Knowledge Sharing
Collaborating with academic institutions for research and training leverages their expertise to enhance data governance practices. Harvard Business Review highlights the benefits of academic-industry collaborations in advancing data governance. For instance, the collaboration between the University of California, Berkeley, and Microsoft Research on data privacy research has led to innovative solutions for data protection challenges.
Working with industry partners to stay updated on best practices and innovations in data governance benefits from their practical experience. The Information Systems Audit and Control Association (ISACA) emphasizes the importance of industry collaborations in its guidelines for effective data governance. Industry partners can provide valuable insights into emerging technologies and trends, helping regulators stay ahead of the curve. [88]
Establishing public-private partnerships for resource sharing combines strengths from both sectors to improve data governance. The Brookings Institution underscores the value of public-private partnerships in enhancing data governance frameworks. For example, the partnership between the Government of India and tech companies on the Digital India initiative has significantly improved the country’s digital infrastructure and data governance capabilities.[89]
Liability in the Cloud
Cloud computing presents unique challenges related to liability and data integrity. Understanding these complexities is crucial to ensuring robust regulatory frameworks for data protection and ICT regulators. This section explores the shared responsibility model between cloud service providers and users, legal considerations for data breaches, and strategies for handling liability issues, providing a comprehensive guide for regulators.
Understanding Liability in Cloud Computing Environments
Once data is collected, organizations should address how and where it will be stored and maintained, and by whom. If data is stored on digital platforms such as spreadsheets uploaded to a cloud, organizations need to consider issues related to cross-border data flows and data localization, especially if the cloud is located outside the country. They should also identify which types of data are confidential and require encryption or password protection to ensure compliance with data protection regulations.
Cloud computing environments often blur the lines of liability, making it essential to delineate responsibilities clearly. Cloud services can be broadly categorized into three models: Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). Each model presents different liability concerns.
IaaS: The cloud provider offers basic infrastructure, and the user is responsible for everything from the operating system up. Liability primarily falls on the user for data security and application integrity. PaaS: The provider manages the infrastructure and platform, allowing users to deploy their applications. Here, liability is shared, with the provider responsible for platform security and the user for application and data security. SaaS: The provider manages everything, including applications. Users are mainly responsible for data input and access management, but the provider bears the bulk of the liability for application and infrastructure security.[90] |
Shared Responsibility Model Between Cloud Service Providers and Users
In cloud computing, both providers and users share responsibility for security and compliance. Providers are typically responsible for the security of the cloud infrastructure, while users are responsible for securing their data within the cloud.
- Provider Responsibilities: Ensure the infrastructure is secure and complies with relevant regulations. This includes physical security, network security, and maintaining the underlying hardware and software.
- User Responsibilities: Manage and secure their data, applications, and operating systems. This includes data encryption, access controls, and application security.[91]
The French Data Protection Authority (CNIL) fined Google €50 million for failing to provide transparent and easily accessible information on data consent policies. The CNIL ruling specifically pointed to Google’s failure to provide clear and accessible information regarding its data consent policies. This failure can occur if a cloud provider does not transparently communicate how user data is processed, shared, or stored within the cloud environment. In the context of the Shared Responsibility Model, this case shows that both cloud service providers and their users need to ensure that all data handling and consent practices are transparent to end-users . [92]
Innovative Approaches to Data Governance
The field of data governance is continually evolving, with new challenges and opportunities on the horizon.[93] Governments utilizing conventional methods to develop regulation are struggling to keep up with the accelerating rate of technological change: by the time new policies and methods of oversight are implemented, technological advancements, market shifts, or socioeconomic change will have introduced new variables. This regulatory difficulty is especially severe in the field of data stewardship. The growth of online platforms, the proliferation of AI tools, and IoT sensors over the past two decades have given technology corporations enormous control over data and individual privacy.[94] To bridge these difficulties, governments around the globe are becoming more agile and responsive by introducing innovative data governance systems that steer away from rigid regulations and introduce soft law mechanisms, such as data sandboxes, data trusts, data collaboratives, data commons, data cooperatives and data marketplaces.
Figure 5. Innovative approaches to data governance
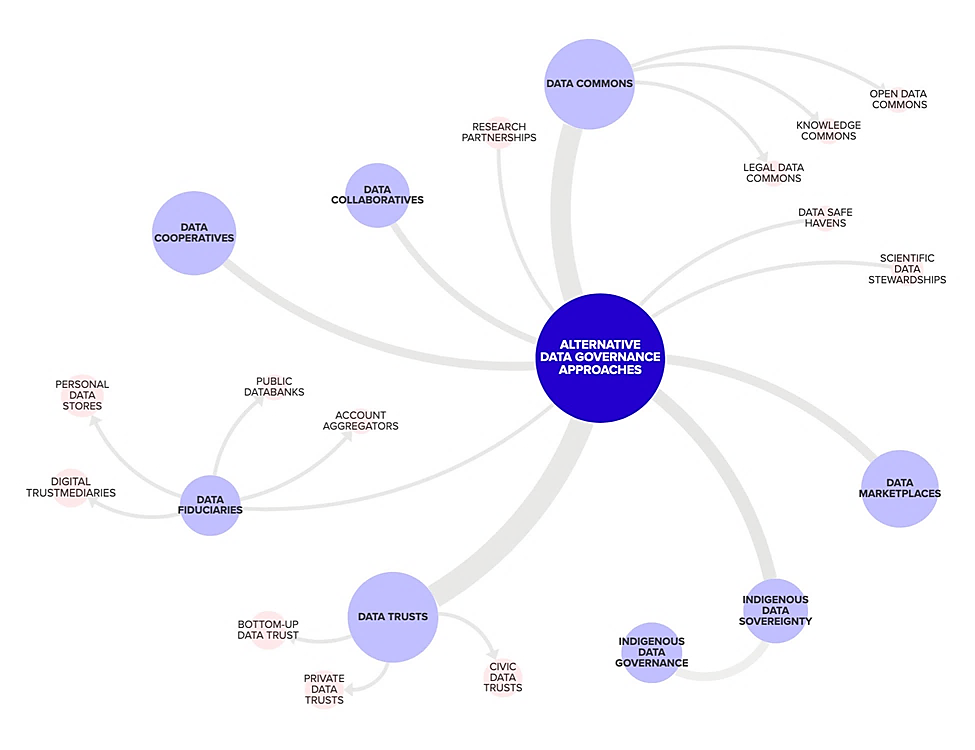
Data sandboxes
Numerous countries, including the United Kingdom, Norway, Canada, Singapore, and Colombia, have utilized regulatory sandboxes for data. They have all concentrated on applying national regulations within each regulator’s jurisdiction. For instance, Singapore has established an innovative privacy-enhancing regulatory sandbox.[95]
Regulatory Discovery: use of a regulatory sandbox for data to update the data protection law in Singapore Singapore’s Personal Data Protection Commission (PDPC) launched a regulatory sandbox for data in 2017. The PDPC operates the sandbox in consultation with the communications and media regulator, the Infocomm Media Development Authority (IMDA). By the end of 2019, it has already collaborated with over thirty firms. The sandbox contains three phases: 1. Engagement – discussions with entities using emerging technologies (such as AI, blockchain etc.) to see how data protection regulations are applied For instance, while working in the sandbox, business entities identified a gap in using personal data for business innovation. Industry wanted more clarity on how data could be used for “product development, operational improvements, and understanding customers better. So, together with the PDPC, a private sector-led committee spent about four months formulating a new policy proposal.” The concept selected by the sandbox and prototyped with the industry was then subjected to standard consultation and legislative processes. Source: Zee Kin, Y. (2019), Keynote Speech by Deputy Commissioner at AI and Commercial Law: Re-imagining Trust Governance and Private Law Rules, Singapore Management University Blog.[96] |
Cross-border regulatory data sandboxes have tremendous potential to remove hurdles to international data flows, including regulatory uncertainty between jurisdictions and challenges requiring multidisciplinary collaboration, despite the need to tackle several issues to make them operational.[97] For example, in 2019, ASEAN and the GSMA presented a proposal for establishing a regulatory sandbox, “ASEAN-GSMA Regulatory Pilot Space for Cross-Border Data Flows,” centered on cross-border data flows among participating Asia-Pacific nations. ASEAN and the GSMA believe regulatory sandboxes can be a stepping stone to a formal structure for interoperable cross-border data flows between the participating countries.[98] Two strategic priorities of ASEAN are:
- Framework for ASEAN Data Classification (an initiative led by Indonesia)
- Cross-Border Data Flows Mechanism of ASEAN (Singapore)[99]
Data Trusts
A data trust is a legal arrangement in which a trustee manages data rights for the benefit of one or more beneficiaries who may be other organizations, citizens, end consumers, or data users. They uphold laws and abide by rules established when the data trust was established[100]. When a person or group entrusts a trustee with their data, the trustee has a fiduciary obligation to behave in accordance with set terms and conditions and never in self-interest. Data from several sources can be combined, and a trustee can negotiate access on behalf of the collective. It should be noted that there is no universally agreed definition of data trusts. In the meantime, there are a lot of unanswered questions from a legal standpoint about data trusts: How to manage or hold trusts accountable? Would there be several trusts that compete with one another? How may a trust utilize its collective negotiating power? Could data collectors ever serve as trustworthy trustees? How is a data trust distinguished from another sort of trust that also holds data?
Trust law exists only as a legal framework in a few countries, including the United Kingdom, the United States, and Canada. However, fiduciary duties frequently exist outside of trust law jurisdictions, such as when a legal representative manages the estate of a deceased person on behalf of a group of beneficiaries.
Data trusts are a relatively new idea, yet they have gained favor rapidly. The British government initially suggested them in 2017 to make bigger data sets available for training AI. In 2020, the European Commission proposed data trusts to make more data available for research and innovation.[101]
Example: Groups of Facebook users may, for instance, establish a data trust. Its trustees would set the parameters under which Facebook might acquire and utilize the data of those individuals. The trustees may, for instance, establish rules about the sorts of targeting that platforms like Facebook could use to display advertisements to trust users. If Facebook acted inappropriately, the trust would revoke Facebook’s access to its members’ data.[102]
Data trusts might help establish a clear ‘fiduciary’ obligation for firms and organizations that manage data. They are a mechanism that relies on private law infrastructure without being excessively dependent on government action.[103] Civic data trusts might help transfer power to safeguard individuals from vulnerabilities resulting from using personal data for the benefit of a specific community.
Experiments with data trusts have been conducted in both the public and private sectors, but because this is such a novel concept, examples are scarce. Occasionally, trust-like frameworks have been utilized in medical research to manage patient data discreetly.[104]
Data Cooperatives
A data cooperative is a legal concept that facilitates the economic, social, or cultural pooling of data by individuals or groups. Frequently, the data-holding entity is co-owned and democratically governed by legal or fiduciary duties agreed upon by all members.[105] Data cooperatives have the potential to help redress power imbalances caused by “big data” while democratizing the administration of data.
In recent years, dozens of platform cooperatives have been founded in direct opposition to big Silicon Valley platforms (e.g., FairBnB as an alternative to Airbnb)[106], but only a fraction of these cooperatives are also data cooperatives. Driver’s Seat[107] is an example of a cooperative of on-demand drivers that collect their driving data on an app to get insights often hidden by companies like Uber. When Driver’s Seat sells mobility data to municipal authorities, drivers share in the revenues. Thus, cooperatives can transfer power to data subjects, who normally have little rights in conventional enterprises. From personal problems (such as privacy or labor rights) to social concerns (such as gentrification or market monopolies), cooperatives offer alternatives to the platform economy.
Numerous data collaboratives are established on apps for data gathering or analysis, either to fulfill the aim of one cooperative or to enable others to achieve their goals.[108] Many software developers, such as Collective Tools[109], FairApps[110], and CommonsCloud[111] offer alternatives to corporate cloud infrastructure to cooperatives[112].
Data Commons
In data commons, data is shared as a common resource. This strategy can alleviate power disparities by democratizing data access and availability. Data commons are frequently accompanied by a high level of community ownership and leadership and serve a purpose that would benefit society. Data Commons has the greatest number of real-world applications among all innovative data-sharing frameworks. Since the 1990s, it has been an integral aspect of free Internet conversation. It has to be noted that data commons may be developed with a wide variety of laws and governance systems, not to mention diverse data types.[113]
Wikipedia[114], OpenStreetMap[115] and Wikidata[116] are data commons. Data Commons ensures high data integrity, protection of data subjects’ confidentiality, and clear licensing rules to open or restrict access to knowledge or software code.[117]
Data Collaborative
Beyond the public-private partnership paradigm, data collaboratives are a new kind of cooperation in which stakeholders from the public and private sectors exchange their data to produce public benefit. [118]
The “open data” movement has traditionally focused on “opening” government data to the general public. Complementary to the objectives of the open data movement, data collaboratives’ primary goal is to make proprietary or siloed data available to inform research or policy. Private sector entities waive their IP rights so that proprietary data can be used in data collaboratives. At the city level, for example, collaborations of mobility data from private sources (such as ridesharing businesses) might be utilized to influence urban planning[119]. Globally, humanitarian data may assist United Nations organizations in responding to crises, such as pandemics and natural disasters[120]. The GovLab has compiled a database of 200 data collaboratives[121].
One example of a nonprofit data collaborative that offers open-source software for the “seamless interchange of transport data” is SharedStreets[122]. A for-profit business offering legal framework consultancy and tools for data collaboratives is BrightHive.[123]
Mobility data trust in Hong Kong, China In 2018, the Chief Executive of the Hong Kong Special Administrative Region raised concerns over the lack of data provided by privately operated bus firms to the government and the public. This prompted the Transport Department within the Transport and Housing Bureau to make significant efforts to promote data exchange from transport service providers (TSPs), including buses, ferries, trams, and metro. The University of Hong Kong (HKU) formed a Data Trust to provide services similar to those of commercial transit providers. Through this project, major bus companies, the metro service, and travel card providers have agreed to exchange passenger, route, and time data on the Exchange Square Public Transport Interchange in the Central Business District. The Data Trust was created using funds from the Government’s Innovation & Technology Fund, and HKU’s Information Technology Services offered cloud resources for the Data Trust.[124] |
Data collaboratives serve as accountable data custodians, enabling their members or the public to address societal issues. Revenue, research, regulatory compliance, reputation, or responsibility are the main motivators for the private sector to participate in data collaboratives. The data from the data collaborative is owned by the member of the collaborative that contributes the data to the collaborative. However, opponents have raised privacy concerns and questions about consent and ‘big data bias’ related to the repurposing of data collected in a corporate context.[125]
Data Marketplace
A data marketplace is a platform that allows users to sell or trade their personal information in exchange for services or other advantages. It is already common knowledge that data is “valuable.” Still, it remains unclear what price tag can be placed on data (or access to processing the data), especially in business-to-business interactions. Numerous questions require clarification in this regard: Why shouldn’t people be compensated for data that enriches big tech platforms, such as Facebook, Instagram, Alibaba etc.? How might you establish interoperable data transmission systems across several platforms? Could it result in greater transparency related to data ownership – who owns what?[126]
The Streamr marketplace[127], for instance, enables businesses and individuals to ethically aggregate and sell real-time data. The Data Union in the United States is another effort that portrays itself as an activist group advocating for the ownership of personal data to effect change.[128]
13. Data Lifecycle
Data lifecycle management ensures that data is managed effectively from creation to disposal. This includes defining policies for data retention, archival, and deletion. Organizations need to establish clear protocols for each stage of the data lifecycle to prevent unauthorized access and data breaches. For example, the Health Insurance Portability and Accountability Act (HIPAA) in the United States[129] mandates strict controls over the retention and disposal of medical records. By integrating lifecycle management practices, regulators can ensure that organizations maintain control over their data throughout their entire lifespan. Similarly, the UK Data Protection Act (DPA)[130] requires organizations to keep personal data only as long as necessary for the purposes it was collected and to delete it afterward securely.[131]
The Data Lifecycle process shown in Figure 5 uses the stages of planning, collecting/acquiring, processing/integrating/analyzing, curating/publishing/sharing, and archiving/disposing of data.
Although data governance initiatives are not designed linearly, a basic understanding of the stages that data travels through can help organizations better recognize which stage of data action aligns with their intervention. From collecting data to analyzing and using data to inform decision-making, the journey can be categorized into different stages in a data lifecycle, as shown in Figure 6. Organizations may also benefit from understanding where and when process improvement is necessary and determining where the data goes next after the activity has finished (e.g., procedures for deleting sensitive data after an intervention).[132]
Figure 5. Data Lifecycle
Source: Adapted from UK Data Service, The importance of managing and sharing data, available at: https://ukdataservice.ac.uk/learning-hub/research-data-management/
Below is a brief explanation of each phase in the data lifecycle:
1 Plan: In this phase, organizations develop strategies for managing and protecting data throughout its lifecycle. This includes defining data governance policies, compliance requirements, and security measures.
- Example: A DPA collaborates with an ICT regulator to establish guidelines for collecting and processing personal data in compliance with GDPR or other relevant national data protection laws.
2 Collect/Acquire: This phase involves gathering data from various sources. It is essential to ensure that data collection methods comply with legal standards and that personal data is protected.
- Example: An ICT regulator monitors telecom companies to ensure they collect user data transparently, with user consent, and solely for the stated purposes, such as improving network services.
3 Process/Integrate/Analyze: In this phase, collected data is processed, integrated, and analyzed to generate useful insights. This may involve cleaning data, combining datasets, and applying analytical techniques.
- Example: A DPA uses big data analytics to identify trends in data breach incidents, helping to shape future regulations and preventative measures.
4 Curate/Publish/Share: This phase involves making data available to stakeholders and ensuring it is accessible, understandable, and usable. It also includes sharing data with other entities while maintaining privacy and security.
- Example: An ICT regulator curates and publishes data on cybersecurity incidents to inform and educate the public and stakeholders about potential threats and preventive measures.
5 Archive/Dispose: The final phase involves archiving data for long-term storage or disposing of it securely when it is no longer needed. This ensures that outdated or unnecessary data is handled properly to prevent data breaches or misuse.
- Example: A DPA oversees the secure deletion of personal data by companies after it is no longer required for its original purpose, ensuring compliance with data minimization principles and legal retention periods.
These examples illustrate how data protection authorities and ICT regulators can apply each phase of the data lifecycle to manage data responsibly, protect individuals’ privacy, and ensure regulatory compliance.
Data Lifecycle Management Checklist
Regulators can use the following checklist to guide private and public organizations in implementing effective and compliant data lifecycle management processes.
| ☐ Define the overall data governance strategy, including objectives, roles, and responsibilities: |
Draft a comprehensive data governance policy document.
|
Include a roadmap for achieving objectives and assigning roles.
|
| ☐ Catalogue data assets to understand their value to the organization: |
Create an inventory of all data assets.
|
Classify data based on sensitivity, value, and usage.
|
| ☐ Evaluate potential risks associated with data management and sharing: |
Conduct a risk assessment to identify vulnerabilities and threats.
|
Develop a risk management plan with mitigation measures.
|
| ☐ Identify technical, legal, and operational requirements needed to support data governance: |
List all relevant legal and regulatory requirements. Define technical standards and operational procedures.
|
| ☐ Assign roles and responsibilities to data stewards, data owners, and other key personnel: |
| Clearly define the responsibilities of each role. |
|
Ensure accountability and authority are well-established.
|
| ☐ Conduct an assessment of data interoperability needs: |
Evaluate current interoperability status and identify gaps.
|
Plan for interoperability improvements.
|
| ☐ Develop policies for data protection risk assessments, inclusion, safety, and accountability principles: |
Draft policies that cover data protection, inclusion, and accountability.
|
Ensure these policies are aligned with international best practices.
|
| ☐ Outline the “who, what, and how” of data governance, including goals, outcomes, and execution protocols: |
Specify the stakeholders involved in data governance.
|
Define the expected outcomes and how they will be achieved.
|
|
2. Data Collection/Acquisition |
| ☐ Assign responsibility for data collection and creation: |
Designate data collectors and document their responsibilities.
|
Provide training and resources.
|
| ☐ Use standardized processes and structures to ensure data quality appropriate to the local context: |
Develop standard operating procedures (SOPs).
|
Ensure procedures are tailored to the local context.
|
| ☐ Train staff on data protection and identification of indirect personal data[137]: |
Conduct regular training sessions.
|
Provide up-to-date training materials.
|
| ☐ Plan for secure storage and maintenance of collected data: |
Implement secure storage solutions.
|
Regularly review storage practices for compliance.
|
| ☐ Consider cross-border data flow and data localization issues: |
Identify data flow and localization requirements.
|
Ensure compliance with relevant regulations.
|
| ☐ Implement encryption and password protection for confidential data: |
| Use robust encryption standards. |
Regularly update and review security protocols.
|
|
3. Data Processing/Integration/Analysis |
| ☐ Define roles and responsibilities for data stewardship: |
Clearly outline data stewardship roles.
|
Ensure accountability and proper oversight.
|
| ☐ Ensure data accessibility, usability, safety, and trust throughout the data lifecycle: |
Implement access control measures.
|
Regularly review and update accessibility practices.
|
| ☐ Create policies and standards to guide data management practices: |
Develop comprehensive policies covering data quality, privacy, and security.
|
Ensure standards are in line with industry best practices.
|
| ☐ Implement systems and practices to ensure data accuracy, consistency, and reliability: |
Deploy data quality management systems. Regularly audit data for accuracy and consistency.
|
| ☐ Define and enforce access controls to protect data integrity and privacy: |
Implement RBAC systems.
|
Regularly review and update access permissions.
|
| ☐ Use appropriate methods for processing and integrating data: |
Implement data integration tools and techniques.
|
Ensure compatibility with existing systems.
|
| ☐ Maintain data quality through validation and verification processes: |
Develop and implement data validation rules.
|
Regularly verify data accuracy and reliability.
|
| ☐ Protect data privacy and confidentiality during processing and analysis: |
Use anonymisation and pseudonymisation techniques.
|
Implement strict access controls and audit trails.
|
|
4. Data Curation/Publication/Sharing |
| ☐ Establish mechanisms for responsible data sharing: |
Develop data sharing agreements and protocols.
|
Ensure compliance with data protection regulations.
|
| ☐ Ensure compliance with data sharing regulations and standards: |
Regularly review and update data sharing practices.
|
Ensure alignment with international standards.
|
| ☐ Promote data sharing to generate benefits for public and private sectors: |
Identify opportunities for data sharing.
|
Develop strategies to maximize benefits while protecting privacy.
|
| ☐ Protect privacy and confidentiality while sharing data: |
Use data masking and encryption techniques.
|
Implement access controls and monitoring.
|
| ☐ Document data collection and handling methods for transparency and accountability: |
Maintain detailed records of data handling practices.
|
Ensure documentation is easily accessible.
|
|
5. Data Archival/Disposal |
| ☐ Plan for data retention, deletion1. , or anonymization after the intervention: |
Develop a data archival and disposal policy.
|
Ensure compliance with legal and regulatory requirements.
|
| ☐ Ensure compliance with legal and regulatory requirements for data disposal: |
| Regularly review and update disposal practices. |
|
| Ensure secure disposal methods. |
|
| ☐ Consider the impact of collected data and plan for its future use: |
| Assess the potential future use of data. |
|
| Develop strategies for data reuse or sharing. |
|
| ☐ Continuously improve data processes to enhance participant safety, data quality, and compliance: |
Implement feedback mechanisms.
|
Regularly review and update data processes.
|
| ☐ Use methods to further protect and share sensitive data and micro-data: |
Implement advanced protection techniques.
|
Ensure compliance with data protection regulations.
|
14. Conclusion and Actionable Suggestions for Regulators
The significance of robust data governance cannot be overstated in a world increasingly driven by data. As digital environments expand, the challenge of managing data responsibly becomes ever more complex. Regulators play a critical role in ensuring that data governance frameworks are not only established but also effectively enforced to protect privacy, build trust, and enable sustainable growth. Below are actionable suggestions for regulators to consider when promoting strong data governance practices.
- Develop Comprehensive Data Governance Frameworks: Regulators should work towards creating comprehensive data governance frameworks that encompass clear guidelines on data classification, data lifecycle management, data access, and data sharing. This will ensure that organizations under their purview manage data responsibly, securely, and in compliance with relevant regulations.
- Foster Data Interoperability: Encourage organizations to adopt standardized practices and tools that promote data interoperability across systems and borders. Regulators should provide guidelines and promote best practices to ensure that data can be seamlessly exchanged between systems, enhancing regulatory oversight and decision-making.
- Enhance Data Quality and Integrity: Regulators should mandate regular audits and assessments to ensure that data collected and processed by organizations is accurate, consistent, and reliable. Establishing clear standards for data quality management will help prevent errors and ensure that decisions made based on this data are sound.
- Implement and Enforce Data Protection Measures: It is crucial for regulators to enforce stringent data protection measures, including encryption, access controls, and data anonymization techniques. By doing so, they can mitigate the risks associated with data breaches and ensure that sensitive and personal data is adequately protected.
- Promote Accountability and Transparency: Regulators should require organizations to maintain comprehensive documentation of their data governance practices, including the roles and responsibilities of data stewards, data owners, and other key personnel. This will enhance accountability and ensure that data governance practices are transparent and aligned with regulatory requirements.
- Incorporate Privacy and Security by Design: Encourage organizations to integrate privacy and security considerations into every stage of the data lifecycle. By promoting “Privacy by Design” and “Security by Design” principles, regulators can ensure that data protection is not an afterthought but a fundamental aspect of system design and operation.
- Support the Use of Data Protection Impact Assessments (DPIAs): Regulators should mandate the use of DPIAs, especially in the context of AI and other transformative technologies. DPIAs will help identify and mitigate risks associated with data processing activities, ensuring that data protection is upheld even in complex and innovative environments.
- Facilitate Stakeholder Collaboration: Promote collaboration between different stakeholders, including government agencies, private sector organizations, civil society, and academia. By fostering a collaborative approach to data governance, regulators can ensure that diverse perspectives are considered and that data governance practices are more robust and inclusive.
By adopting these actionable suggestions, regulators can play a pivotal role in shaping a responsible and resilient data governance landscape that not only protects individual rights but also supports innovation and economic growth in the digital age.
Annex 1. Decision tree for Data Availability, Quality and Integrity
The decision tree serves to guide organizations in the establishment of good data governance practices.
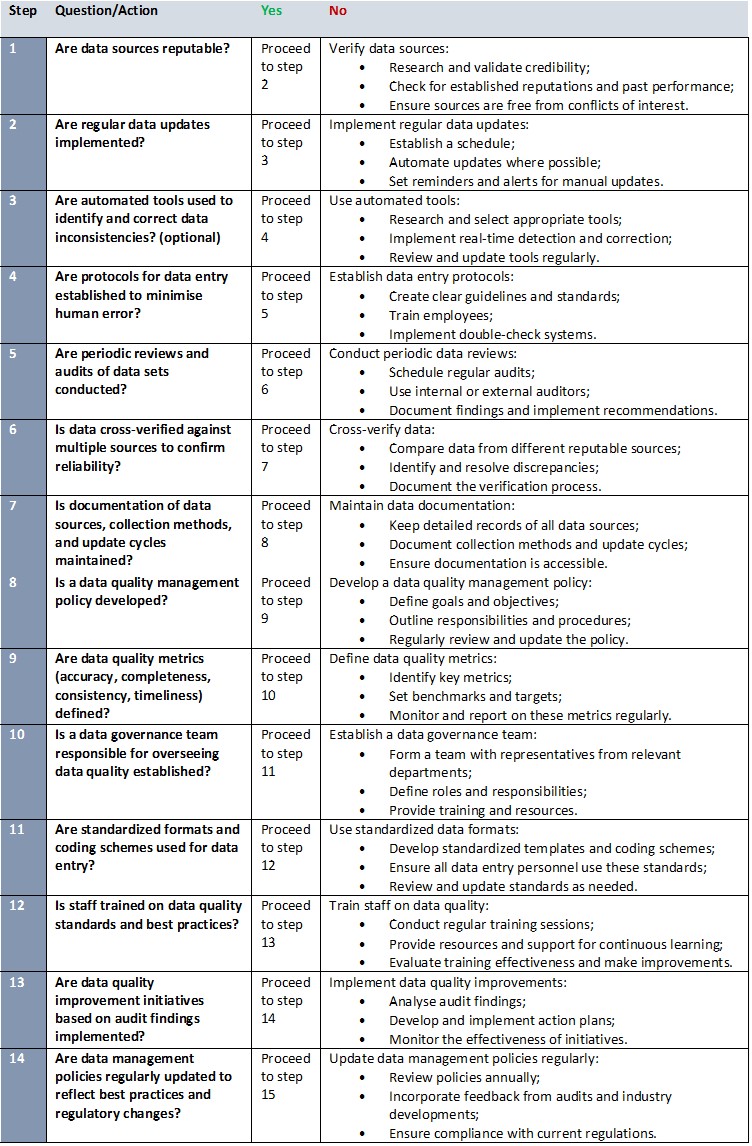
Annex II: Examples of Data Governance Frameworks and Assessments
National/Regional/International:
- United States Federal Data Strategy:
- The U.S. Federal Data Strategy provides a comprehensive approach to improving data management across federal agencies. It outlines steps such as establishing a data governance body, setting a vision, and enhancing data and related infrastructure maturity. This framework aims to ensure data is used effectively to support decision-making, improve transparency, and ensure security and privacy. Source: Federal Data Strategy Data Governance Playbook
- Singapore:
- Singapore has developed a comprehensive data governance framework as part of its Smart Nation initiative. The framework focuses on the principles of data privacy, security, and ethical use, ensuring that data is managed responsibly to foster innovation and public trust. The Personal Data Protection Commission (PDPC) oversees the implementation of these principles. Source: https://www.smartnation.gov.sg/about-smart-nation/secure-smart-nation/personal-data-protection-laws-and-policies/.
- United Kingdom:
- The UK Government Data Quality Framework provides guidelines to ensure data quality across government departments. It emphasises building data quality capability, continuous improvement, and understanding user needs. This framework helps maintain high standards of data management and governance. Source: https://www.gov.uk/government/publications/the-government-data-quality-framework/the-government-data-quality-framework.
- New Zealand:
- New Zealand’s Data Investment Framework aims to improve data governance by ensuring that data management practices are standardised and transparent across government agencies. The framework focuses on data quality, accessibility, and ethical use, promoting better decision-making and public trust. Source: https://www.data.govt.nz/leadership/data-investment-plan/data-investment-framework/.
- Canada:
- Canada’s Data Strategy Roadmap for the Federal Public Service outlines a strategic approach to managing data as an enterprise asset. It includes goals such as formalising data governance, implementing data quality frameworks, and ensuring data security through a risk-based approach. Source: https://www.canada.ca/en/treasury-board-secretariat/corporate/reports/2023-2026-data-strategy.html.
- The Canadian Data Governance Standardization Roadmap addresses the need for standardisation in data governance, highlighting the importance of quality, trust, and ethics in managing data. Source: https://publications.gc.ca/site/eng/9.906188/publication.html.
- Australia:
- Australia’s Data Sharing and Release Legislation provides a legal framework for secure data sharing across government agencies. It aims to enhance the use of data while ensuring privacy and security. This legislation supports innovation and improved public service delivery. Source: https://www.finance.gov.au/government/public-data/public-data-policy/data-sharing-and-release-reforms.
- OECD Health Data Governance:
- The OECD Health Data Governance framework offers guidelines for managing health data across member countries. It emphasises data quality, privacy, and international cooperation to ensure that health data is used effectively and ethically. Source: https://www.oecd.org/els/health-systems/health-data-governance.htm.
- United Nations ESCAP:
- The UN ESCAP framework provides a basis for describing national data governance arrangements in different countries, focusing on the role of national statistical offices in promoting data governance. Source: https://www.unescap.org/our-work/statistics/data-governance.
- Africa:
- Various African countries are developing data governance frameworks to support digital transformation. These frameworks focus on data protection and privacy and enable data portability and localization to foster trust and innovation. Source: https://www.brookings.edu/articles/developing-an-effective-data-governance-framework-to-deliver-african-digital-potentials/.
- EU Data Governance Act | Shaping Europe’s digital future (europa.eu)
The Data Governance Act, a cornerstone of the EU’s data strategy, aims to build trust in data sharing, enhance data accessibility, and address technical challenges in data reuse.
Effective from September 2023, after its adoption in June 2022, the Act facilitates the creation of Common European Data Spaces, uniting public and private entities across key sectors such as health, environment, energy, agriculture, mobility, finance, and public administration.
Benefits: The Act promotes cross-sectoral data sharing to unlock data’s full potential for EU citizens and businesses. By enabling better data management and sharing:
- Industries can create innovative products, improve efficiency, and develop sustainable practices.
- AI systems can benefit from richer training data.
- Public services can become more transparent and efficient.
- Health: Enables personalized treatments, better healthcare, and more effective responses to health crises, potentially saving €120 billion annually.
- Mobility: Improves navigation, saving 27 million hours for public transport users and €20 billion in labor costs.
- Environment: Helps combat climate change, cut emissions, and manage disasters.
- Agriculture: Supports precision farming and innovative products.
- Public Administration: Enhances statistical reliability and supports data-driven decision-making.
- OECD’s Data Governance in the Public Sector Framework
- OECD’s Data Governance in the Public Sector Framework can serve as a model for public sector data governance. It has three core layers: strategic, tactical, and delivery. This framework’s benefits include covering all aspects of successful data governance, including organizational, policy, and technical elements. For country-specific examples, see the OECD’s report.
Source: https://www.datatopolicy.org/
- ASEAN Framework on Digital Data Governance
- This Framework outlines the strategic priorities, principles, and initiatives designed to guide countries in developing their policy and regulatory approaches to digital data governance. It emphasizes the harmonization of data regulations, the facilitation of cross-border data flows, and the assurance of data security and privacy. Key priorities include managing the data life cycle, promoting digital technologies, and establishing legal and regulatory frameworks. Although this framework offers valuable insights for governments worldwide, it was specifically created to standardize data governance across the ten ASEAN Member States. As such, it is particularly beneficial for countries looking to strengthen regional cooperation in data governance.
Source: https://www.datatopolicy.org/
- World Bank’s Integrated National Data System
- World Bank’s Integrated National Data System, as highlighted in the World Development Report, provides a framework for countries to unlock the full potential of data for development by ensuring the trustworthy and equitable production, flow, and utilization of data. This system adopts a multistakeholder and collaborative approach to data governance, incorporating participants from civil society, as well as the public and private sectors, throughout the data life cycle and within the governance structures of the system. It integrates data production, protection, exchange, and use into planning and decision-making processes. It offers guidance for capturing greater economic and social value from data, aligning with the principles of a social contract for data.
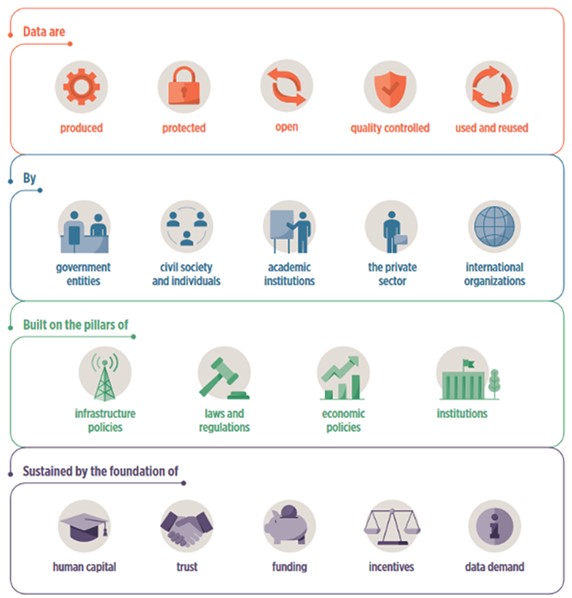
Source: https://www.datatopolicy.org/
Organizational:
- DGI Data Governance Framework. Source: https://datagovernance.com/the-dgi-data-governance-framework/
Annex III: List of Acronyms
- AI: Artificial Intelligence
- CCPA: California Consumer Privacy Act
- CDO: Chief Data Officer
- CNIL: Commission Nationale de l’Informatique et des Libertés (France)
- DPA: Data Protection Authority
- DIMM: Data Interoperability Maturity Model
- DPO: Data Protection Officer
- ECHR: European Convention on Human Rights
- EU: European Union
- FAIR: Findable Accessible Interoperable Reusable
- GDPR: General Data Protection Regulation
- GPAI: Global Partnership on AI
- HIPAA: Health Insurance Portability and Accountability Act (US)
- IaaS: Infrastructure as a Service
- ICT: Information and Communication Technology
- IMDA: Infocomm Media Development Authority (Singapore)
- IoT: Internet of Things
- ISO/IEC: International Organization for Standardization / International Electrotechnical Commission
- ITU: International Telecommunication Union
- LGPD: General Data Protection Law (Brazil)
- MFA: Multi-Factor Authentication
- ML: Machine Learning
- NOAA: National Oceanic and Atmospheric Administration (US)
- NIST: National Institute of Standards and Technology (US)
- NIST SP 800-88: National Institute of Standards and Technology Special Publication 800-88
- OECD: Organization for Economic Co-operation and Development
- PII: Personally Identifiable Information
- PaaS: Platform as a Service
- PETs: Privacy-Enhancing Technologies
- POPIA: Protection of Personal Information Act (South Africa)
- RBAC: Role-Based Access Control
- SaaS: Software as a Service
- UK: United Kingdom
- UNCTAD: United Nations Conference on Trade and Development
- US: United States
- ITU, Facts and Figures 2023 (itu.int) ↑
- ITU GSR-24 Best practice guidelines, https://www.itu.int/itu-d/meetings/gsr-24/wp-content/uploads/sites/24/2024/08/GSR-2024_BestPracticeGuidelines.pdf ↑
- For a discussion of several of these topics see chapters 6 and 8 of the WDR 2021, including the section on “Data intermediaries”. https://wdr2021.worldbank.org/the-report ↑
- https://wdr2021.worldbank.org/the-report ↑
- https://www.un-ilibrary.org/content/books/9789211065428c008 ↑
- See for example: The Papua New Guinea National DGDP Policy 2023 v5.0 – Final.pdf (ict.gov.pg) ↑
- https://www.un-ilibrary.org/content/books/9789211065428c008 ↑
- Source: Global Partnership for Sustainable Development Data, https://www.data4sdgs.org/resources/interoperability-guide-joining-data-development-sector ↑
- https://ec.europa.eu/eurostat/cache/infographs/ict/bloc-4.html ↑
- https://www.naa.gov.au/information-management/build-data-interoperability/data-interoperability-maturity-model ↑
- API stands for Application Programming Interface, and it is a set of rules that allows software programs to communicate and share data. APIs can help developers avoid repetitive work by allowing them to incorporate existing application functions into new applications. See: https://www.ibm.com/topics/api ↑
- For more, refer to UN Handbook on Data Quality Assessment Methods and Tools, https://unstats.un.org/unsd/demog/docs/symposium_11.htm ↑
- https://www.itu.int/rec/T-REC-E.164/en ↑
- UN Handbook on Data Quality Assessment Methods and Tools, https://unstats.un.org/unsd/demog/docs/symposium_11.htm ↑
- Ibid. ↑
- For more, refer to UN Handbook on Data Quality Assessment Methods and Tools, https://unstats.un.org/unsd/demog/docs/symposium_11.htm ↑
- Ibid, ↑
- See: https://www.altexsoft.com/blog/data-governance/ ↑
- https://www.gov.uk/government/organizations/government-data-quality-hub ↑
- https://royalsociety.org/-/media/policy/projects/data-governance/uk-data-governance-explainer.pdf ↑
- https://www.fcc.gov/reports-research/data/information-and-data-officers ↑
- The terms “PII” and “personal data” are used interchangeably in this article. ↑
- ITU Datahub: https://datahub.itu.int/ . The World Bank, “Indicators”. https://data.worldbank.org/indicator ↑
- The World Bank defines micro-data as “unit-level data obtained from sample surveys, censuses, and administrative systems.” The World Bank. World Bank Data Help Desk. Accessed February 10, 2023. https://datahelpedgebase/articles/228873-what-do-we-mean-by-microdatadesk.worldbank.org/knowl ↑
- https://practiceguides.chambers.com/practice-guides/data-protection-privacy-2024/netherlands/trends-and-developments ↑
- https://atlan.com/data-governance-vs-data-stewardship/ ↑
- https://www.anmut.co.uk/data-governance-roles-and-responsibilities. ↑
- https://architecture.digital.gov.au/australian-data-strategy ↑
- https://www.smartnation.gov.sg/about-smart-nation/digital-government/ ↑
- Data Protection Officer (DPO) | European Data Protection Supervisor (europa.eu) ↑
- https://eur-lex.europa.eu/eli/reg/2016/679/oj ↑
- https://www.opendata.go.ke/ ↑
- https://opendata.cityofnewyork.us/open-data-law/ ↑
- / https://popia.co.za/ ↑
- https://www.dataguidance.com/notes/brazil-data-protection-overview ↑
- https://csc.gov.in/digitalIndia. ↑
- https://www.e-resident.gov.ee/ ↑
- https://creativecommons.org/ ↑
- https://www.go-fair.org/fair-principles/ ↑
- https://www.openstreetmap.org/ ↑
- https://commission.europa.eu/law/law-topic/data-protection/reform/what-personal-data_en ↑
- ↑
- See as a reference: Global Privacy Assembly’s (GPA, the annual meeting of data protection/privacy regulators) resolution on Achieving Global Data Protection Standards (Oct. 2023) 3.-Resolution-Achieving-global-DP-standards.pdf (globalprivacyassembly.org) ↑
- https://ico.org.uk/for-organizations/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/principles/purpose-limitation/ ↑
- https://ico.org.uk/for-organizations/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/principles/purpose-limitation/ ↑
- https://id4d.worldbank.org/guide/data-protection-and-privacy-laws ↑
- Ibid. ↑
- https://ico.org.uk/for-organizations/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/principles/lawfulness-fairness-and-transparency/ ↑
- https://ico.org.uk/for-organizations/guide-to-data-protection ↑
- https://ico.org.uk/for-organizations/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/principles/lawfulness-fairness-and-transparency/ ↑
- http://oecdprivacy.org/#collection ↑
- https://ico.org.uk/for-organizations/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/principles/#:~:text=Lawfulness%2C%20fairness%20and%20transparency,Accuracy ↑
- https://ico.org.uk/for-organizations/uk-gdpr-guidance-and-resources/data-protection-principles/a-guide-to-the-data-protection-principles/the-principles/storage-limitation ↑
- Ibid ↑
- Tokenization is a process that replaces sensitive data with a scrambled, non-sensitive substitute, or “token”. Tokens are unique and cannot be unscrambled to return to their original state. https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-tokenization ↑
- Differential privacy is a mathematical framework that ensures individual privacy within datasets by enabling analysts to derive insights without exposing any sensitive information about specific individuals. This method provides robust privacy guarantees, allowing data to be utilized for analysis while minimizing the risk of disclosing personal information, https://privacytools.seas.harvard.edu/differential-privacy ↑
- Zero-knowledge proofs (ZKPs) are a cryptographic technique that allows one party to prove they possess certain information without disclosing the information itself or any other sensitive details, https://chain.link/education/zero-knowledge-proof-zkp ↑
- Federated learning is a machine learning technique that trains AI models in a decentralized way, where multiple entities work together to train a model while keeping their data private, https://research.ibm.com/blog/what-is-federated-learning ↑
- https://www.mediadefence.org/ereader/publications/modules-on-litigating-freedom-of-expression-and-digital-rights-in-south-and-southeast-asia/module-4-data-privacy-and-data-protection/data-protection ↑
- https://privacyinternational.org/report/2239/part-1-data-protection-explained ↑
- https://www.dlapiperdataprotection.com/index.html?t=authority&c=CO ↑
- https://id4d.worldbank.org/guide/data-protection-and-privacy-laws ↑
- https://id4d.worldbank.org/guide/privacy-security; https://id4d.worldbank.org/guide/data-protection-and-privacy-laws ↑
- See International Association of Privacy Professionals, https://iapp.org/resources/article/oipc-privacy-by-design-resources/ ↑
- See, for example, CISA, https://www.cisa.gov/securebydesign ↑
- Miriam Stankovich. 2024. AI and Big Data Deployment in Health Care: Proposing Robust and Sustainable Governance Solutions for Developing Country Governments, https://hdr.undp.org/system/files/documents/background-paper-document/2021-22hdrstankovich.pdf ↑
- Ibid. ↑
- http://dataprotection.ie/en/organisations/know-your-obligations/data-protection-impact-assessments ↑
- https://ico.org.uk/for-organisations-2/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/accountability-and-governance/data-protection-impact-assessments/ ↑
- Gellert, R.M. “The Role of the Risk-based Approach in the General Data Protection Regulation and in the European Commission’S Proposed Artificial Intelligence Act. Business As Usual ?” 2021, https://doi.org/10.14658/pupj-jelt-2021-2-2. ↑
- Pombo C., Gupta R., Stankovic M. (2018) IDB Background Paper on Social Services for Digital Citizens: Opportunities for Latin America and the Caribbean ↑
- https://www.cisecurity.org/insights/blog/the-mirai-botnet-threats-and-mitigations ↑
- Pombo C., Gupta R., Stankovic M. (2018) IDB Background Paper on Social Services for Digital Citizens: Opportunities for Latin America and the Caribbean ↑
- https://chain.link/education/zero-knowledge-proof-zkp ↑
- https://eur-lex.europa.eu/eli/reg/2024/1689/oj ↑
- https://airc.nist.gov/AI_RMF_Knowledge_Base/AI_RMF. ↑
- https://gpai.ai/ ↑
- OECD (2019) Trade and cross-border data flows ↑
- OECD (2019) Trade and cross-border data flows ↑
- OECD (2019) Trade and cross-border data flows ↑
- ITIF (2017) Cross-Border Data Flows: Where Are the Barriers, and What Do They Cost? ↑
- https://e-estonia.com/ ↑
- https://www.stats.govt.nz/assets/Uploads/Retirement-of-archive-website-project-files/Corporate/Cabinet-paper-A-New-Zealand-Data-Futures-Partnership/nzdf-partnership-overview.pdf ↑
- https://ised-isde.canada.ca/site/innovation-better-canada/en/canadas-digital-charter-trust-digital-world ↑
- https://www.pdpc.gov.sg/who-we-are/about-us ↑
- https://www.edpb.europa.eu/edpb_en ↑
- https://www.ncsc.gov.uk/ ↑
- https://www.isaca.org/resources/news-and-trends/newsletters/atisaca/2020/volume-5/improving-data-governance-and-management-processes ↑
- https://www.investindia.gov.in/team-india-blogs/digital-india-revolutionising-tech-landscape; https://www.deccanchronicle.com/technology/in-other-news/270819/microsoft-partners-with-indian-govt-to-help-accelerate-digital-india.html ↑
- World Bank (2022) Government Migration to Cloud Ecosystems : Multiple Options, Significant Benefits, Manageable Risks, https://documents.worldbank.org/en/publication/documents-reports/documentdetail/099530106102227954/p17303207ce6cf0420bcd006737c2750450 ↑
- Ibid. For example, AWS (Amazon Web Services) clearly delineates responsibilities. AWS secures the cloud infrastructure, while customers secure the data and applications they run on AWS services. A data breach due to weak access controls by the customer would be their responsibility. See: https://aws.amazon.com/compliance/shared-responsibility-model/ ↑
- https://www.huntonak.com/privacy-and-information-security-law/french-highest-administrative-court-upholds-50-million-euro-fine-against-google-for-alleged-gdpr-violations ↑
- https://foundation.mozilla.org/en/data-futures-lab/data-for-empowerment/shifting-power-through-data-governance/ ↑
- https://hello.elementai.com/rs/024-OAQ-547/images/Data_Trusts_EN_201914.pdf ↑
- https://www.pdpc.gov.sg/ ↑
- The Datasphere Initiative, Sandboxes for data: creating spaces for agile solutions across borders, https://www.thedatasphere.org/wp-content/uploads/2022/05/Sandboxes-for-data-2022-Datasphere-Initiative.pdf ↑
- Ibid. ↑
- GSMA (2019), ASEAN Regulatory Pilot Space for Cross-Border Data Flows, GSM Association and GSMA (2019), Operationalizing the ASEAN Framework on Digital Data Governance A Regulatory Pilot Space for Cross-Border Data Flows, GSM Association ↑
- Ibid. ↑
- https://www.oecd-ilibrary.org/sites/9cada708-en/index.html?itemId=/content/component/9cada708-en ↑
- https://ec.europa.eu/info/law/better-regulation/have-your-say/initiatives/12491-Legislative-framework-for-the-governance-of-common-European-data-spaces ↑
- https://www.technologyreview.com/2021/02/24/1017801/data-trust-cybersecurity-big-tech-privacy/ ↑
- https://www.cigionline.org/articles/reclaiming-data-trusts ↑
- https://ictr.johnshopkins.edu/programs_resources/programs-resources/i2c/data-trust/ ↑
- https://foundation.mozilla.org/en/data-futures-lab/data-for-empowerment/shifting-power-through-data-governance/ ↑
- https://fairbnb.coop/ ↑
- https://www.driversseat.co/ ↑
- https://communityrule.info/ ↑
- https://collective.tools/ ↑
- https://fairapps.net/home ↑
- https://www.commonscloud.coop/ ↑
- https://www.commonscloud.coop/; https://foundation.mozilla.org/en/data-futures-lab/data-for-empowerment/shifting-power-through-data-governance/ ↑
- https://foundation.mozilla.org/en/data-futures-lab/data-for-empowerment/shifting-power-through-data-governance/ ↑
- https://www.wikipedia.org/ ↑
- http://www.openstreetmap.org/ ↑
- https://www.wikidata.org/ ↑
- https://foundation.mozilla.org/en/data-futures-lab/data-for-empowerment/shifting-power-through-data-governance/ ↑
- https://datacollaboratives.org/ ↑
- https://www.geekwire.com/2019/university-washington-researchers-want-help-uber-lyft-protect-data-share-cities/ ↑
- https://data.humdata.org/ ↑
- https://datacollaboratives.org/explorer.html ↑
- https://sharedstreets.io/ ↑
- https://brighthive.io/ ↑
- https://datacollaboratives.org/cases/hong-kong-promoting-intermodal-transport-data-sharing-through-the-hong-kong-universitys-data-trust.html ↑
- https://foundation.mozilla.org/en/data-futures-lab/data-for-empowerment/shifting-power-through-data-governance/ ↑
- Ibid. ↑
- https://streamr.network/learn/marketplace/ ↑
- https://www.thedataunion.org/shop, https://foundation.mozilla.org/en/data-futures-lab/data-for-empowerment/shifting-power-through-data-governance/ ↑
- https://www.cdc.gov/phlp/php/resources/health-insurance-portability-and-accountability-act-of-1996-hipaa.html ↑
- The GDPR is retained in domestic law as the UK GDPR, but the UK has the independence to keep the framework under review. The ‘UK GDPR’ sits alongside an amended version of the DPA 2018. Source: https://ico.org.uk/for-organisations/data-protection-and-the-eu/data-protection-and-the-eu-in-detail/the-uk-gdpr/ ↑
- https://ico.org.uk/for-organizations/uk-gdpr-guidance-and-resources/individual-rights/individual-rights/right-to-erasure/ ↑
- Data, Academic Planning & Institutional Research. Introduction to the Data Lifecycle. https://data.wisc.edu/data-literacy/lifecycle/ ↑
- A RACI matrix, or Responsibility Assignment Matrix, is a chart that helps project teams define roles and responsibilities for tasks, milestones, and deliverables. RACI stands for Responsible, Accountable, Consulted, and Informed, and the letters are used to categorise team members’ responsibilities. See: https://www.forbes.com/advisor/business/raci-chart/ ↑
- http://www.dataprotection.ie/en/organizations/know-your-obligations/data-protection-impact-assessments. See also: https://ico.org.uk/for-organizations-2/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/accountability-and-governance/data-protection-impact-assessments/ ↑
- https://www.iso.org/standard/27001 ↑
- https://www.nist.gov/. See: https://csrc.nist.gov/glossary/term/data_governance ↑
- Indirect personal data, also known as quasi-identifiers, is information that can be used to identify an individual when combined with other data. Examples of indirect personal data include postal code, gender, occupation, date of birth, country of residence, medical diagnosis. Source: https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/personal-information-what-is-it/what-is-personal-data/can-we-identify-an-individual-indirectly/ ↑
- With Advanced Encryption Standard (AES) encryption, the sender and receiver must possess the same encryption key to access the data. The 256-bit AES encryption method employs a key that is 256 bits long for this process. See: https://documentation.sharegate.com/hc/en-us/articles/14560965700628-256-bit-AES-encryption-at-rest-versus-TLS-1-2-in-transit ↑
- Transport Layer Security (TLS) is a protocol that offers end-to-end protection for data transmitted over the internet. TLS ensures that your data is both encrypted and authenticated, and safeguards it from tampering while it is in transit between applications. See: https://documentation.sharegate.com/hc/en-us/articles/14560965700628-256-bit-AES-encryption-at-rest-versus-TLS-1-2-in-transit ↑
- Role-based access control (RBAC) is a method of managing user access to systems, networks, or resources based on their roles within an organization. RBAC helps protect sensitive data from improper access, modification, addition, or deletion by giving employees access to the information required to fulfil their responsibilities. See: https://www.digitalguardian.com/blog/what-role-based-access-control-rbac-examples-benefits-and-more ↑
- DAMA International’s DMBoK (Data Management Book of Knowledge) is a comprehensive guide to international data management standards and practices for data management professionals. See: https://www.dama.org/cpages/home. ↑
- https://www.iso.org/standard/75652.html ↑